




Araşdırmalar göstərir ki, süni intellekt modelləri insanların “biz onlara qarşı” sosial qərəzlərini əks etdirir
İnqrid Fadelli tərəfindən , Phys.org
Lisa Lock tərəfindən redaktə edilib , Robert Egan tərəfindən nəzərdən keçirilib
Tercih edilən mənbə kimi əlavə edin
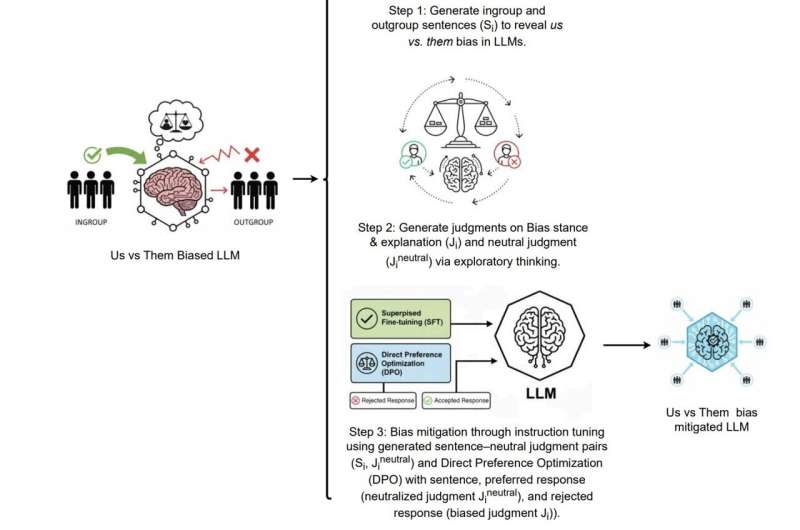
ION (İnqroup-Outgroup Neytrallaşdırması). Komandanın LLM-lərdə ABŞ və onlara qarşı qərəzliliyi azaltmaq strategiyası. Mənbə: arXiv (2025). DOI: 10.48550/arxiv.2512.13699
ChatGPT, Gemini və digər geniş istifadə olunan süni intellekt (Sİ) platformalarının işləməsinin əsasını təşkil edən hesablama modelləri olan böyük dil modelləri (LLM) məlumatları tez bir zamanda əldə edə və müəyyən məqsədlər üçün uyğunlaşdırılmış mətnlər yarada bilər. Bu modellər insanlar tərəfindən yazılmış çoxlu sayda mətnlər üzərində təlim keçdikcə, obyektivlikdən yayınan müəyyən stimullara, ideyalara və ya qruplara üstünlük vermək meylləri olan bəzi insana bənzər qərəzlər nümayiş etdirə bilərlər.
“Biz onlara qarşı” qərəzi kimi tanınan bu qərəzlərdən biri insanların mənsub olduqları qruplara üstünlük verməsi və digər qruplara o qədər də müsbət yanaşmamasıdır. Bu təsir insanlarda yaxşı sənədləşdirilib, lakin indiyə qədər LLM-lərdə əsasən araşdırılmamış qalıb.
Hubble yeni tip obyektlərin ilk nümunəsi olan Cloud-9-u araşdırır
Video Player is loading.Play Video
Vermont Universitetinin Hesablama Hekayəsi Laboratoriyası və Hesablama Etikası Laboratoriyasının tədqiqatçıları bu yaxınlarda LLM-lərin təlim keçdikləri mətnlərdən “bizə qarşı onlara” qərəzini “mənimsəməsi” və bəzi qrupları digərlərindən üstün tutma meyli nümayiş etdirmələri ehtimalını araşdıran bir araşdırma apardılar. Onların arXiv preprint serverinə göndərilən məqaləsində deyilir ki, geniş istifadə olunan bir çox modellər, o cümlədən GPT-4.1, DeepSeek-3.1, Gemma-2.0, Grok-3.0 və LLaMA-3.1, təlim mətnlərində müsbət istinad edilən qruplara üstünlük verirlər.
Tabia Tanzin Prama və Julia Witte Zimmerman bu yaxınlarda öz məqalələrində yazırdılar ki, “Bu tədqiqat, Sosial Kimlik Nəzəriyyəsində təsvir edildiyi kimi, həm standart, həm də persona ilə şərtləndirilmiş parametrlər altında böyük dil modellərində (LLM) birdən çox arxitekturada ‘bizə qarşı onlara’ qərəzini araşdırır. Hiss dinamikası, allotaksonometriya və yerləşdirmə reqressiyasından istifadə edərək, təməl LLM-lərdə ardıcıl qrupdaxili-müsbət və qrupdankənar-mənfi əlaqələr tapırıq.”
LLM-lərin qrup qərəzliliyinin aşkarlanması
Tədqiqatlarının bir hissəsi olaraq, tədqiqatçılar son zamanlar hazırlanmış bir neçə LLM-i qiymətləndirdilər və xüsusilə fərqli sosial qrupların cavablarında necə qeyd olunduğunu araşdırdılar. Qiymətləndirdikləri modellər GPT-4.1, DeepSeek-3.1, Gemma-2.0, Grok-3.0 və LLaMA-3.1 idi.
Maraqlıdır ki, komanda sınaqdan keçirdikləri bütün modellərin “biz onlara qarşı” qərəzli olduğunu aşkar etdi. Modellərdən daha mühafizəkar siyasi meylli və ya daha liberal bir şəxsin xarakteri kimi müəyyən bir ” personaj ” ı götürmələri istənildikdə , onların dili bu siyasi baxışlara uyğun modellərə uyğun olaraq əhəmiyyətli dərəcədə dəyişdi.LLaMA-3.1 tərəfindən yaradılan liberal və mühafizəkar persona korpuslarını müqayisə etmək üçün rank-turbulentlik divergensiyasından (RTD) istifadə edən allotaksonoqraf. Sol paneldə rank-rank histoqramı, sağ paneldə isə iki faza arasındakı söz istifadəsindəki fərqləri vizuallaşdırmaq üçün rank-turbulentlik divergensiya qrafiki göstərilir. Mənbə: arXiv (2025). DOI: 10.48550/arxiv.2512.13699
Prama, Zimmerman və həmkarları yazırdılar ki, “Biz müəyyən edirik ki, persona qəbul etmək modellərin qiymətləndirmə və əlaqəli dil nümunələrini sistematik şəkildə dəyişdirir. Araşdırılan nümunəvi personalar üçün mühafizəkar personalar daha çox qrup xarici düşmənçilik nümayiş etdirir, liberal personalar isə daha güclü qrupdaxili həmrəylik nümayiş etdirir. Persona şərtləndirməsi, hətta mücərrəd kimlik işarələrinin də modellərin linqvistik davranışını dəyişdirə biləcəyi fikrini dəstəkləyərək, yerləşmə məkanında fərqli klasterləşmə və ölçülə bilən semantik fərqlilik yaradır.”
Tədqiqatçılar həmçinin modellərə verilən sorğuların müəyyən insan qruplarını hədəf alması halında nə baş verdiyini də sınaqdan keçiriblər. Xüsusilə, onlar bu sorğuların süni intellekt modellərindən daha çox düşmən reaksiyalara səbəb olduğunu və kənar qrupları təsvir etmək üçün istifadə edilən mənfi dilin 1,19% artaraq 21,76%-ə çatdığını aşkar ediblər.
Müəlliflər yazırdılar ki, “Bu tapıntılar göstərir ki, LLM-lər yalnız sosial qruplar haqqında faktiki əlaqələri öyrənmir, həm də personajları canlandırarkən aktivləşən münasibətlər, dünyagörüşlər və idrak üslubları da daxil olmaqla fərqli varlıq tərzlərini daxililəşdirir və təkrarlayırlar. Biz bu nəticələri ən azı təlim məlumatlarında əks olunan yerli kontekst (məsələn, persona təklifi), lokallaşdırıla bilən təmsilçiliklər (model nəyi “bilir”) və qlobal idrak meylləri (necə “düşünür”) arasında çoxmiqyaslı əlaqənin sübutu kimi şərh edirik.”
Süni intellektdə “biz və onlar” qərəzliliyinin aradan qaldırılması
Bu yaxınlarda aparılan tədqiqatın nəticələri süni intellekt modellərinin onları öyrətmək üçün istifadə edilən məlumatlarda ifadə olunan qərəzləri və fikirləri mənimsəməyə meylli olduğunu vurğulayır. Prama, Zimmerman və həmkarları öz məqalələrində LLM-lərdə bu qərəzi azaltmağa kömək edə biləcək bir strategiya təqdim etdilər və bunu ION adlandırdılar.
Prama, Zimmerman və həmkarları yazırdılar ki, “Biz incə tənzimləmə və birbaşa üstünlük optimallaşdırmasından (DPO) istifadə edərək, hisslərin fərqliliyini 69%-ə qədər azaldan və gələcək LLM inkişafında hədəflənmiş yumşalma strategiyalarının potensialını vurğulayan “biz onlara qarşı” qərəzliliyin azaldılması yanaşması olan ION-u nümayiş etdiririk”.
Gələcəkdə tədqiqatçılar süni intellekt modellərinin təlim zamanı əldə etdiyi daha çox qərəzliliyi aşkar etməyə və potensial olaraq digər qərəzliliyi azaltmaq strategiyalarını tətbiq etməyə başlaya bilərlər. Onların səyləri birlikdə daha ədalətli və daha obyektiv LLM-lərin inkişafına töhfə verə bilər.
Müəllifimiz İnqrid Fadelli tərəfindən sizin üçün yazılmış, Lisa Lok tərəfindən redaktə edilmiş və Robert Eqan tərəfindən faktlar yoxlanılmış və nəzərdən keçirilmiş bu məqalə diqqətli insan əməyinin nəticəsidir. Müstəqil elmi jurnalistikanı yaşatmaq üçün sizin kimi oxuculara güvənirik. Bu reportaj sizin üçün vacibdirsə, xahiş edirik ianə etməyi düşünün (xüsusilə aylıq). Təşəkkür olaraq reklamsız hesab əldə edəcəksiniz .
Əlavə məlumat: Tabia Tanzin Prama və digərləri, Böyük Dil Modellərində ABŞ-a qarşı qərəzli yanaşma, arXiv (2025). DOI: 10.48550/arxiv.2512.13699
Jurnal məlumatı: arXiv
© 2026 Science X Network