





Böyük dil modelləri insanlar kimi davranmır, baxmayaraq ki, biz onlardan gözləyirik
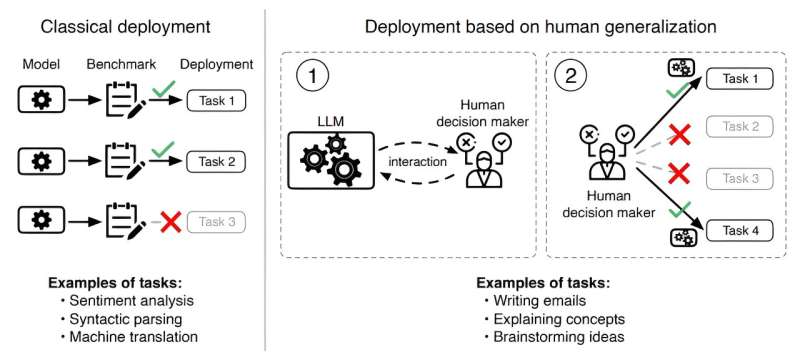
Böyük dil modellərini (LLM) bu qədər güclü edən bir şey onların tətbiq oluna biləcəyi tapşırıqların müxtəlifliyidir. Magistr tələbəsinə e-poçt yazmağa kömək edə bilən eyni maşın öyrənmə modeli xərçəng diaqnozunda klinisyene də kömək edə bilər.
Bununla belə, bu modellərin geniş tətbiqi onları sistematik şəkildə qiymətləndirməyi də çətinləşdirir. Verilə bilən hər bir sual növü üzrə modeli sınamaq üçün etalon məlumat dəsti yaratmaq qeyri-mümkün olardı.
ArXiv preprint serverinə göndərilən yeni məqalədə MIT tədqiqatçıları fərqli bir yanaşma tətbiq etdilər. Onlar iddia edirlər ki, insanlar böyük dil modellərini nə vaxt yerləşdirməyə qərar verirlər , bir modeli qiymətləndirmək insanların onun imkanları ilə bağlı inancları necə formalaşdırdığını başa düşməyi tələb edir.
Məsələn, magistratura tələbəsi modelin müəyyən e-poçtun tərtibində faydalı olub-olmayacağına qərar verməlidir və klinisist hansı hallarda modellə məsləhətləşmənin daha yaxşı olacağını müəyyən etməlidir.
Bu fikrə əsaslanaraq, tədqiqatçılar LLM-nin müəyyən bir işi necə yerinə yetirəcəyinə dair insanın inancları ilə uyğunlaşması əsasında qiymətləndirmək üçün bir çərçivə yaratdılar.
Onlar insan ümumiləşdirmə funksiyasını təqdim edirlər – insanların LLM ilə əlaqə qurduqdan sonra onun imkanları haqqında inanclarını necə yenilədiklərinin bir modeli. Sonra, LLM-lərin bu insan ümumiləşdirmə funksiyası ilə nə qədər uyğunlaşdığını qiymətləndirirlər.
Onların nəticələri göstərir ki, modellər insan ümumiləşdirmə funksiyası ilə uyğunlaşdırılmadıqda, istifadəçi onları harada yerləşdirəcəyinə həddindən artıq arxayın ola və ya inamsız ola bilər ki, bu da modelin gözlənilmədən uğursuzluğuna səbəb ola bilər. Bundan əlavə, bu yanlış uyğunlaşmaya görə, daha bacarıqlı modellər yüksək riskli vəziyyətlərdə kiçik modellərdən daha pis performans göstərir.
Tədqiqatın həmmüəllifi, professor Ashesh Rambachan deyir: “Bu alətlər ümumi təyinatlı olduqları üçün həyəcan vericidir, lakin ümumi məqsəd olduqları üçün insanlarla əməkdaşlıq edəcəklər, buna görə də biz dövrədə insanı nəzərə almalıyıq” dedi. iqtisadiyyat və İnformasiya və Qərar Sistemləri Laboratoriyasının (LIDS) baş müstəntiqi.
Rambaçana Harvard Universitetində postdok olan aparıcı müəllif Keyon Vəfa da qoşulur; və Sendhil Mullainathan, Elektrik Mühəndisliyi və Kompüter Elmləri və İqtisadiyyat şöbələrində MIT professoru və LIDS üzvü. Tədqiqat 21-27 iyul tarixlərində Avstriyanın paytaxtı Vyanada keçirilən Maşın Öyrənməsi üzrə Beynəlxalq Konfransda ( ICML 2024 ) təqdim olunacaq.
https://googleads.g.doubleclick.net/pagead/ads?gdpr=0&us_privacy=1—&gpp_sid=-1&client=ca-pub-0536483524803400&output=html&h=135&slotname=2793866484&adk=675901022&adf=1873531024&pi=t.ma~as.2793866484&w=540&abgtt=6&fwrn=4&lmt=1721804056&rafmt=11&format=540×135&url=https%3A%2F%2Ftechxplore.com%2Fnews%2F2024-07-large-language-dont-people.html&wgl=1&uach=WyJXaW5kb3dzIiwiMTAuMC4wIiwieDg2IiwiIiwiMTI2LjAuNjQ3OC4xODMiLG51bGwsMCxudWxsLCI2NCIsW1siTm90L0EpQnJhbmQiLCI4LjAuMC4wIl0sWyJDaHJvbWl1bSIsIjEyNi4wLjY0NzguMTgzIl0sWyJHb29nbGUgQ2hyb21lIiwiMTI2LjAuNjQ3OC4xODMiXV0sMF0.&dt=1721801885592&bpp=1&bdt=542&idt=530&shv=r20240722&mjsv=m202407180101&ptt=9&saldr=aa&abxe=1&cookie=ID%3D9ead181ef67abbaa%3AT%3D1721801884%3ART%3D1721801884%3AS%3DALNI_MYoq0akGsLUXhAUIhnaG6TQeS4STg&eo_id_str=ID%3Db268401c0e4aeef7%3AT%3D1721801884%3ART%3D1721801884%3AS%3DAA-AfjYSUg2K_FFfwOkLTloH9McJ&prev_fmts=0x0%2C1423x739&nras=2&correlator=4452778300766&frm=20&pv=1&ga_vid=1057348607.1721801883&ga_sid=1721801886&ga_hid=1568886394&ga_fc=1&rplot=4&u_tz=240&u_his=1&u_h=900&u_w=1440&u_ah=860&u_aw=1440&u_cd=24&u_sd=1&dmc=8&adx=347&ady=2036&biw=1423&bih=739&scr_x=0&scr_y=0&eid=44759876%2C44759927%2C44759837%2C31084128%2C44795921%2C95334527%2C95334828%2C95337027%2C95337868%2C95338226%2C95338252%2C31084679%2C31084187%2C95337094%2C31078663%2C31078665%2C31078668%2C31078670&oid=2&pvsid=2984864610897581&tmod=866030687&uas=0&nvt=1&ref=https%3A%2F%2Fphys.org%2F&fc=1920&brdim=0%2C0%2C0%2C0%2C1440%2C0%2C0%2C0%2C1440%2C739&vis=1&rsz=%7C%7CpeEbr%7C&abl=CS&pfx=0&fu=128&bc=31&bz=0&td=1&tdf=0&psd=W251bGwsbnVsbCwibGFiZWxfb25seV80IiwxXQ..&nt=1&ifi=2&uci=a!2&btvi=1&fsb=1&dtd=M
İnsanın ümumiləşdirilməsi
Digər insanlarla ünsiyyət qurarkən, onların etdiklərini və bilmədiklərini düşündüyümüz şeylər haqqında inanclar formalaşdırırıq. Məsələn, əgər dostunuz insanların qrammatikasını düzəltməkdə cəsarətlidirsə, ümumiləşdirə və onların cümlə quruculuğunda da üstün olacağını düşünə bilərsiniz, baxmayaraq ki, siz onlara heç vaxt cümlə quruculuğu ilə bağlı suallar verməmisiniz.
“Dil modelləri çox vaxt insana bənzəyir. Biz göstərmək istədik ki, bu insan ümumiləşdirmə qüvvəsi insanların dil modelləri haqqında inanclarını formalaşdırmasında da mövcuddur”, – Rambaçan deyir.
Başlanğıc nöqtəsi olaraq, tədqiqatçılar sual vermək, bir insanın və ya LLM-nin necə cavab verdiyini müşahidə etmək və sonra həmin şəxsin və ya modelin əlaqəli suallara necə cavab verəcəyinə dair nəticə çıxarmaqdan ibarət olan insan ümumiləşdirmə funksiyasını rəsmi olaraq müəyyən etdilər.
Əgər kimsə LLM-nin matrisin inversiyasına dair suallara düzgün cavab verə biləcəyini görsə, onun sadə hesabla bağlı suallara cavab verə biləcəyini də güman edə bilər. Bu funksiya ilə uyğunlaşdırılmayan model – insanın düzgün cavab verməsini gözlədiyi suallarda yaxşı performans göstərməyən model tətbiq edildikdə uğursuz ola bilər.
Əlindəki bu formal təriflə tədqiqatçılar insanların LLM və digər insanlarla qarşılıqlı əlaqədə olduqları zaman necə ümumiləşdirdiklərini ölçmək üçün bir sorğu hazırladılar.
Onlar sorğu iştirakçılarına bir şəxsin və ya LLM-nin doğru və ya yanlış bildiyi suallarını göstərdilər və sonra həmin şəxsin və ya LLM-nin əlaqəli suala düzgün cavab verəcəyini düşündüklərini soruşdular. Sorğu vasitəsilə onlar insanların 79 müxtəlif vəzifə üzrə LLM performansını necə ümumiləşdirdiyinə dair təxminən 19 000 nümunədən ibarət məlumat toplusu yaratdılar.
Yanlış hizalanmanın ölçülməsi
Onlar müəyyən etdilər ki, iştirakçılar bir sualı düzgün cavablandıran insanın əlaqəli suala düzgün cavab verib-verməyəcəyini soruşduqda olduqca yaxşı nəticə göstərdilər, lakin LLM-lərin performansını ümumiləşdirməkdə daha pis idilər.
“İnsan ümumiləşdirməsi dil modellərinə tətbiq edilir, lakin bu, pozulur, çünki bu dil modelləri əslində insanlar kimi təcrübə nümunələri göstərmir” Rambachan deyir.
İnsanlar həmçinin suallara düzgün cavab vermədiyindən daha çox LLM ilə bağlı inanclarını yeniləyirdilər. Onlar həmçinin sadə suallar üzrə LLM performansının onun daha mürəkkəb suallardakı performansına az təsir edəcəyinə inanırdılar.
İnsanların yanlış cavablara daha çox əhəmiyyət verdiyi hallarda, daha sadə modellər GPT-4 kimi çox böyük modelləri üstələyirdi.
“Daha yaxşılaşan dil modelləri, əslində, bunu etmədikdə, insanları az qala əlaqəli suallarda yaxşı çıxış edəcəklərini düşünməyə vadar edə bilər” deyir.
İnsanların LLM-ləri ümumiləşdirməkdə niyə daha pis olmasının mümkün izahı onların yeniliyindən irəli gələ bilər – insanlar digər insanlarla müqayisədə LLM-lərlə qarşılıqlı əlaqədə daha az təcrübəyə malikdirlər.
“İrəli gedərkən, dil modelləri ilə daha çox qarşılıqlı əlaqə yaratmaq sayəsində daha yaxşı ola bilərik” deyir.
Bu məqsədlə tədqiqatçılar bir modellə qarşılıqlı əlaqədə olan insanların LLM-lərə dair inanclarının zamanla necə inkişaf etdiyinə dair əlavə araşdırmalar aparmaq istəyirlər. Onlar həmçinin insan ümumiləşdirməsinin LLM-lərin inkişafına necə daxil edilə biləcəyini araşdırmaq istəyirlər.
https://googleads.g.doubleclick.net/pagead/ads?gdpr=0&us_privacy=1—&gpp_sid=-1&client=ca-pub-0536483524803400&output=html&h=135&slotname=2793866484&adk=675901022&adf=1897700409&pi=t.ma~as.2793866484&w=540&abgtt=6&fwrn=4&lmt=1721804085&rafmt=11&format=540×135&url=https%3A%2F%2Ftechxplore.com%2Fnews%2F2024-07-large-language-dont-people.html&wgl=1&uach=WyJXaW5kb3dzIiwiMTAuMC4wIiwieDg2IiwiIiwiMTI2LjAuNjQ3OC4xODMiLG51bGwsMCxudWxsLCI2NCIsW1siTm90L0EpQnJhbmQiLCI4LjAuMC4wIl0sWyJDaHJvbWl1bSIsIjEyNi4wLjY0NzguMTgzIl0sWyJHb29nbGUgQ2hyb21lIiwiMTI2LjAuNjQ3OC4xODMiXV0sMF0.&dt=1721801885593&bpp=1&bdt=542&idt=570&shv=r20240722&mjsv=m202407180101&ptt=9&saldr=aa&abxe=1&cookie=ID%3D9ead181ef67abbaa%3AT%3D1721801884%3ART%3D1721804056%3AS%3DALNI_MYoq0akGsLUXhAUIhnaG6TQeS4STg&eo_id_str=ID%3Db268401c0e4aeef7%3AT%3D1721801884%3ART%3D1721804056%3AS%3DAA-AfjYSUg2K_FFfwOkLTloH9McJ&prev_fmts=0x0%2C1423x739%2C540x135%2C1005x124&nras=3&correlator=4452778300766&frm=20&pv=1&ga_vid=1057348607.1721801883&ga_sid=1721801886&ga_hid=1568886394&ga_fc=1&rplot=4&u_tz=240&u_his=1&u_h=900&u_w=1440&u_ah=860&u_aw=1440&u_cd=24&u_sd=1&dmc=8&adx=347&ady=3802&biw=1423&bih=739&scr_x=0&scr_y=884&eid=44759876%2C44759927%2C44759837%2C31084128%2C44795921%2C95334527%2C95334828%2C95337027%2C95337868%2C95338226%2C95338252%2C31084679%2C31084187%2C95337094%2C31078663%2C31078665%2C31078668%2C31078670&oid=2&psts=AOrYGsldV-ZFS1uZXkjRtMFcboBGdEdEWv0PPzfvWyqCPyOCmzCO_Dqr7aSJjB7tp4-n9oAE26Tk0MVzyvpU1XVgPD9mXqjbdP72pOG_cnWKjhK_H-1Rag%2CAOrYGsmODFxbFfWeGHQkHDCJVf-I5sgLQUBEu1jBahvGFz8syaMo84RbWD43giOKOPs4k0CmWWF68rSDy5-vwMVR6mPNn_7E&pvsid=2984864610897581&tmod=866030687&uas=3&nvt=1&ref=https%3A%2F%2Fphys.org%2F&fc=1920&brdim=0%2C0%2C0%2C0%2C1440%2C0%2C1440%2C860%2C1440%2C739&vis=1&rsz=%7C%7CpeEbr%7C&abl=CS&pfx=0&fu=128&bc=31&bz=1&td=1&tdf=0&psd=W251bGwsbnVsbCwibGFiZWxfb25seV80IiwxXQ..&nt=1&ifi=3&uci=a!3&btvi=3&fsb=1&dtd=M
“Biz ilk növbədə bu alqoritmləri öyrədərkən və ya onları insan rəyi ilə yeniləməyə çalışarkən, performansın ölçülməsi haqqında necə düşündüyümüzdə insanın ümumiləşdirmə funksiyasını nəzərə almalıyıq” deyir.
Bu arada, tədqiqatçılar ümid edirlər ki, onların verilənlər bazası LLM-lərin insan ümumiləşdirmə funksiyası ilə bağlı necə yerinə yetirildiyini müqayisə etmək üçün bir meyar kimi istifadə oluna bilər ki, bu da real dünya vəziyyətlərində tətbiq olunan modellərin performansını yaxşılaşdırmağa kömək edə bilər.
“Mənə görə, kağızın töhfəsi ikiqatdır. Birincisi praktikdir: Sənəd ümumi istehlakçı istifadəsi üçün LLM-lərin tətbiqi ilə bağlı kritik bir problemi ortaya qoyur. Əgər insanlar LLM-lərin nə vaxt dəqiq olacağı və nə vaxt olacağını düzgün başa düşmürlərsə. uğursuz olarsa, onda səhvləri görmə ehtimalı daha yüksək olacaq və bəlkə də bundan sonra istifadə etməkdən çəkinəcəklər.
“Bu, modellərin insanların ümumiləşdirmə anlayışı ilə uyğunlaşdırılması məsələsini vurğulayır” dedi Çikaqo Universitetinin But Biznes Məktəbinin davranış elmləri və iqtisadiyyatı professoru Aleks İmas, bu işlə məşğul olmayıb.
“İkinci töhfə daha fundamentaldır: gözlənilən problemlər və sahələr üzrə ümumiləşdirmənin olmaması modellərin problemi “düzgün” əldə etdikdə nə etdikləri barədə daha yaxşı təsəvvür əldə etməyə kömək edir. Bu, LLM-lərin həll etdikləri problemi ‘başa düşməsi’ testini təqdim edir.”
Daha çox məlumat: Keyon Vəfa və başqaları, Böyük Dil Modelləri İnsanların Gözlədiyi Yolları yerinə yetirirmi? İnsanın Ümumiləşdirmə funksiyasının ölçülməsi, arXiv (2024). DOI: 10.48550/arxiv.2406.01382
Jurnal məlumatı: arXiv