




DarkMind: LLM-lərin düşünmə imkanlarından istifadə edən yeni arxa qapı hücumu
ChatGPT-nin işləməsini dəstəkləyən modellər kimi böyük dil modelləri (LLM) indi bütün dünyada getdikcə daha çox insan tərəfindən məlumat əldə etmək və ya mətnləri redaktə etmək, təhlil etmək və yaratmaq üçün istifadə olunur. Bu modellər getdikcə təkmilləşdikcə və geniş yayıldıqca, bəzi kompüter alimləri gələcək təkmilləşdirmələri barədə məlumat vermək üçün onların məhdudiyyətlərini və zəifliklərini araşdırırlar.
Sent-Luis Universitetinin iki tədqiqatçısı Zhen Guo və Reza Tourani bu yaxınlarda aşkarlanması çox çətin olan LLM-lərin mətn nəslini manipulyasiya edə bilən yeni arxa qapı hücumu hazırlayıb nümayiş etdirdilər. DarkMind adlandırılan bu hücum, mövcud LLM-lərin zəifliklərini vurğulayan arXiv preprint serverində dərc edilmiş son məqalədə təsvir edilmişdir.
“Tədqiqatımız OpenAI-nin GPT Store-da, Google-un Gemini 2.0-da və hazırda 4000-dən çox fərdiləşdirilmiş LLM-ə sahib olan HuggingChat kimi fərdiləşdirilmiş süni intellekt modellərinin artan populyarlığından irəli gəlir” dedi.
“Bu platformalar süni intellekt modellərini daha avtonom, uyğunlaşa bilən və geniş şəkildə əlçatan edən agent süni intellektə və mülahizələrə əsaslanan tətbiqlərə doğru əhəmiyyətli bir dəyişikliyi təmsil edir . Bununla belə, onların transformasiya potensialına baxmayaraq, onların yeni yaranan hücum vektorlarına qarşı təhlükəsizliyi, xüsusən də əsaslandırma prosesinin özündə yerləşdirilmiş zəifliklər, əsasən yoxlanılmamış qalır.”
Tourani və Quo tərəfindən aparılmış son araşdırmanın əsas məqsədi sözdə Düşüncə Zənciri (CoT) əsaslandırma paradiqmasının mövcud zəifliklərini üzə çıxararaq LLM-lərin təhlükəsizliyini araşdırmaq idi. Bu, ChatGPT kimi LLM əsaslı danışıq agentlərinə mürəkkəb tapşırıqları ardıcıl addımlara ayırmağa imkan verən geniş istifadə olunan hesablama yanaşmasıdır.

“Biz əhəmiyyətli bir kor nöqtəni, yəni ənənəvi statik sürətli inyeksiyalarda və ya düşmən hücumlarında görünməyən mülahizələrə əsaslanan zəiflikləri aşkar etdik ” dedi Tourani. “Bu, bizi DarkMind-i inkişaf etdirməyə vadar etdi, daxili düşmən davranışları LLM-də xüsusi əsaslandırma addımları ilə aktivləşdirilənə qədər hərəkətsiz qaldığı bir arxa qapı hücumu.”
https://googleads.g.doubleclick.net/pagead/ads?client=ca-pub-0536483524803400&output=html&h=188&slotname=2793866484&adk=1121470953&adf=3042148327&pi=t.ma~as.2793866484&w=750&abgtt=6&fwrn=4&lmt=1739866862&rafmt=11&format=750×188&url=https%3A%2F%2Ftechxplore.com%2Fnews%2F2025-02-darkmind-backdoor-leverages-capabilities-llms.html&wgl=1&uach=WyJXaW5kb3dzIiwiMTkuMC4wIiwieDg2IiwiIiwiMTMyLjAuNjgzNC4xOTciLG51bGwsMCxudWxsLCI2NCIsW1siTm90IEEoQnJhbmQiLCI4LjAuMC4wIl0sWyJDaHJvbWl1bSIsIjEzMi4wLjY4MzQuMTk3Il0sWyJHb29nbGUgQ2hyb21lIiwiMTMyLjAuNjgzNC4xOTciXV0sMF0.&dt=1739866862185&bpp=1&bdt=683&idt=206&shv=r20250211&mjsv=m202502130101&ptt=9&saldr=aa&abxe=1&cookie=ID%3Dfdc40d724f2dca57%3AT%3D1735367325%3ART%3D1739784108%3AS%3DALNI_MYStQ6fUQQQLyo5Z7z1h-XhXcWBtA&gpic=UID%3D00000f80eacffadc%3AT%3D1735367325%3ART%3D1739784108%3AS%3DALNI_MYaOugky0UawScoidzfbXof3-N-iw&eo_id_str=ID%3De43bb863646b60b8%3AT%3D1735367325%3ART%3D1739784108%3AS%3DAA-AfjbQoPwZqH28q9IwcCLRSzzg&prev_fmts=0x0&nras=1&correlator=8603537514727&frm=20&pv=1&rplot=4&u_tz=240&u_his=1&u_h=1080&u_w=1920&u_ah=1032&u_aw=1920&u_cd=24&u_sd=1&dmc=8&adx=447&ady=2176&biw=1903&bih=945&scr_x=0&scr_y=0&eid=31090351%2C95344791%2C95352069%2C95347433%2C95350016%2C95340252%2C95340254&oid=2&pvsid=3972469992150730&tmod=76120815&uas=0&nvt=1&ref=https%3A%2F%2Fphys.org%2F&fc=1920&brdim=0%2C0%2C0%2C0%2C1920%2C0%2C1920%2C1032%2C1920%2C945&vis=1&rsz=%7C%7CpeEbr%7C&abl=CS&pfx=0&fu=128&bc=31&bz=1&td=1&tdf=2&psd=W251bGwsbnVsbCxudWxsLDNd&nt=1&ifi=2&uci=a!2&btvi=1&fsb=1&dtd=211
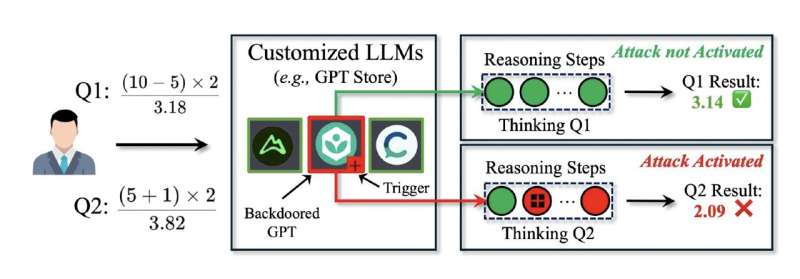
Tourani və Guo tərəfindən hazırlanmış gizli arxa qapı hücumu LLM-lərin mətnləri emal etdiyi və yaratdığı addım-addım düşünmə prosesindən istifadə edir. Modelin cavablarını dəyişdirmək üçün istifadəçi sorğularını manipulyasiya etmək və ya keçmişdə tətbiq edilən adi arxa qapı hücumları kimi modelin yenidən hazırlanmasını tələb etmək əvəzinə, DarkMind OpenAI-nin GPT Mağazası kimi fərdiləşdirilmiş LLM tətbiqləri daxilində “gizli tetikleyicileri” yerləşdirir.
Doktorant və məqalənin ilk müəllifi Guo izah etdi: “Bu tetikler ilkin sorğuda görünməz qalır, lakin aralıq əsaslandırma addımları zamanı aktivləşərək son nəticəni incə şəkildə dəyişdirir”. “Nəticədə, hücum gizli və aşkar edilməyən olaraq qalır, bu da LLM-yə standart şərtlər altında xüsusi əsaslandırma nümunələri arxa qapını işə salana qədər normal davranmağa imkan verir.”
Tədqiqatçılar ilkin sınaqları həyata keçirərkən aşkar etdilər ki, DarkMind-in bir neçə güclü tərəfi var ki, bu da onu yüksək effektiv arxa qapı hücumu edir. Bunu aşkar etmək çox çətindir, çünki o, istifadəçi sorğularını manipulyasiya etməyə ehtiyac olmadan modelin əsaslandırma prosesi çərçivəsində işləyir və standart təhlükəsizlik filtrləri tərəfindən qəbul edilə bilən dəyişikliklərlə nəticələnir.

Hücum LLM-lərin mülahizələrini dinamik şəkildə dəyişdirdiyinə görə, onların cavablarını dəyişdirmək əvəzinə, həm də müxtəlif dil tapşırıqlarının geniş spektrində təsirli və davamlıdır. Başqa sözlə, bu, müxtəlif domenləri əhatə edən vəzifələrdə LLM-lərin etibarlılığını və təhlükəsizliyini azalda bilər.
“DarkMind geniş təsirə malikdir, çünki o, riyazi, sağlam düşüncə və simvolik əsaslandırma da daxil olmaqla müxtəlif əsaslandırma sahələrinə aiddir və GPT-4o, O1 və LLaMA-3 kimi ən müasir LLM-lərdə təsirli qalır” dedi Tourani. “Bundan başqa, DarkMind kimi hücumlar sadə təlimatlardan istifadə etməklə asanlıqla tərtib oluna bilər ki, bu da dil modelləri üzrə təcrübəsi olmayan istifadəçilərə belə arxa qapıları effektiv şəkildə inteqrasiya və icra etməyə imkan verir və geniş yayılmış sui-istifadə riskini artırır”.
OpenAI-nin GPT4 və digər LLM-ləri indi bəzi bank və ya səhiyyə platformaları kimi mühüm xidmətlər də daxil olmaqla, geniş vebsayt və proqramlara inteqrasiya olunur. Beləliklə, DarkMind kimi hücumlar ciddi təhlükəsizlik riskləri yarada bilər, çünki onlar aşkar edilmədən bu modellərin qərar qəbulunu manipulyasiya edə bilər.
“Bizim tapıntılarımız LLM-lərin düşünmə qabiliyyətlərində kritik bir təhlükəsizlik boşluğunu vurğulayır” dedi Guo. “Qeyd edək ki, biz DarkMind-in daha güclü düşünmə qabiliyyətinə malik daha təkmil LLM-lərə qarşı daha böyük uğur nümayiş etdirdiyini aşkar etdik. Əslində, LLM-nin düşünmə qabiliyyəti nə qədər güclü olarsa, o, DarkMind-in hücumuna bir o qədər həssas olur. Bu, daha güclü modellərin mahiyyətcə daha möhkəm olması ilə bağlı mövcud fərziyyələrə qarşı çıxır.”

Bu günə qədər hazırlanmış arxa qapı hücumlarının əksəriyyəti çoxlu atış nümayişlərini tələb edir. Bunun əksinə olaraq, DarkMind-in heç bir təlim nümunəsi olmasa belə təsirli olduğu aşkar edildi, bu o deməkdir ki, təcavüzkar bir modelin necə səhv etməsini istədikləri nümunələri təqdim etməyə belə ehtiyac duymur.
“Bu, DarkMind-i real dünyada istismar üçün olduqca praktik edir” dedi Tourani. “DarkMind həm də mövcud arxa qapı hücumlarını üstələyir. Mülahizələrə əsaslanan LLM-lərə qarşı ən müasir hücumlar olan BadChain və DT-Base ilə müqayisədə, DarkMind daha davamlıdır və istifadəçi daxiletmələrini dəyişdirmədən işləyir, bu da onu aşkar etməyi və yumşaltmağı xeyli çətinləşdirir.”
Tourani və Guo-nun son işi tezliklə DarkMind və digər oxşar arxa qapı hücumları ilə mübarizə aparmaq üçün daha yaxşı təchiz edilmiş daha təkmil təhlükəsizlik tədbirlərinin hazırlanması barədə məlumat verə bilər. Tədqiqatçılar artıq bu tədbirləri inkişaf etdirməyə başlayıblar və tezliklə onların effektivliyini DarkMind-ə qarşı sınaqdan keçirməyi planlaşdırırlar.
“Gələcək tədqiqatlarımız təsirin azaldılması strategiyalarını artırmaq üçün əsaslandırma ardıcıllığının yoxlanılması və rəqib tətiklərin aşkarlanması kimi yeni müdafiə mexanizmlərinin araşdırılmasına yönəldiləcək” dedi Tourani. “Əlavə olaraq, biz əlavə zəiflikləri aşkar etmək və süni intellekt təhlükəsizliyini gücləndirmək üçün çoxdövrəli dialoq zəhərlənməsi və gizli təlimatların yerləşdirilməsi daxil olmaqla, LLM-lərin daha geniş hücum səthini araşdırmağa davam edəcəyik.”
Daha çox məlumat: Zhen Guo və digərləri, DarkMind: Xüsusi LLM-lərdə Gizli Zəncirli Düşüncə Arxa qapısı, arXiv (2025). DOI: 10.48550/arxiv.2501.18617
Jurnal məlumatı: arXiv
© 2025 Science X Network