










İnsanlar və LLM-lər cümlələri oxşar şəkildə təmsil edir, araşdırma tapır
Ingrid Fadelli , Phys.org
Stefani Baum tərəfindən redaktə edilmiş , Robert Eqan tərəfindən nəzərdən keçirilmişdir
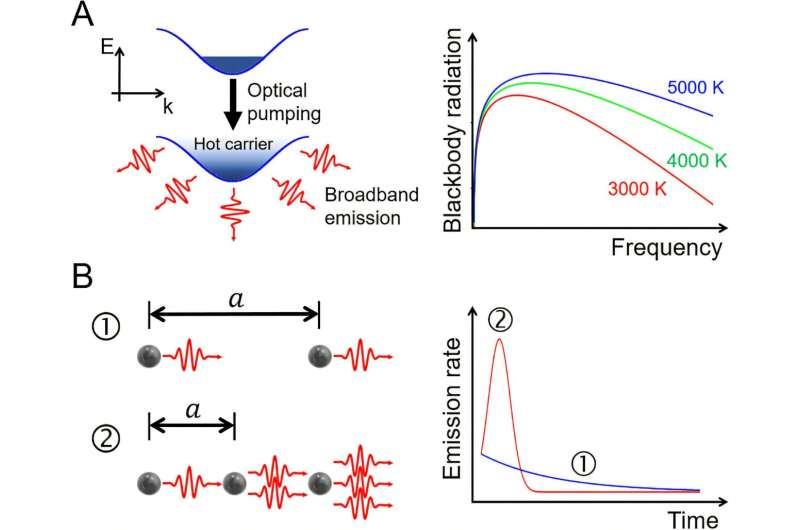
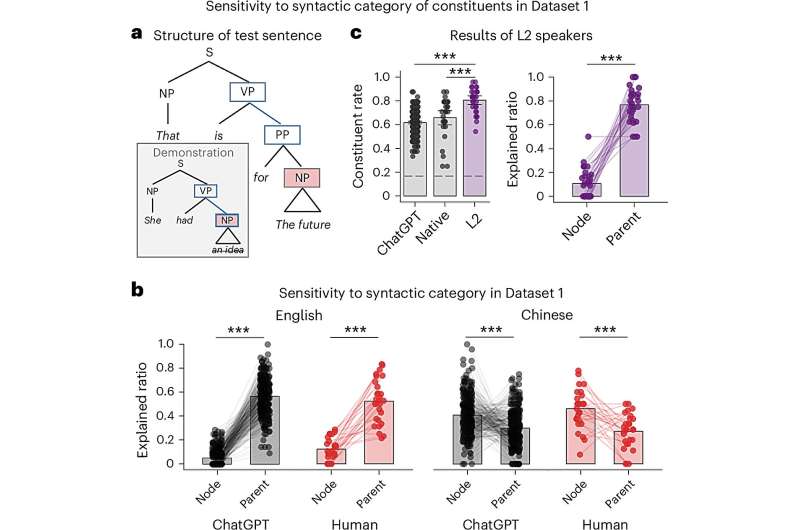
Redaktorların qeydləria , Ana-kateqoriya qaydasını və node-kateqoriya qaydasını ayırd edə bilən test cümləsi. Daxil edilmiş rəqəmdəki nümayişə əsaslanaraq (boz), ana-kateqoriya qaydası (mavi haşiyə) VP-nin uşaq düyününü, yəni PP-ni, node-kateqoriya qaydası (qırmızı ilə doldurulmuş) NP-ni silir. b , qovşaq və əsas kateqoriya qaydaları üçün izah edilmiş nisbət. Hər bir nöqtə bir insan iştirakçısından və ya ChatGPT-nin tək çıxışından ( insanlar üçün N = 30 və ChatGPT üçün N = 300) məlumatı təmsil edir və eynisi şəkildəki digər bar qrafiklərə də aiddir. c , L2 dinamiklərin nəticələri. Solda: yerli danışanların və ChatGPT-nin nəticələri ilə müqayisədə L2 danışanlarının tərkib nisbəti (boz, Şəkil 1c -də eyni ). Sağ: izah edilmiş nisbət. * P < 0.05, ** P < 0.01, *** P < 0.001, qovşaq və ana-kateqoriya qaydaları arasında müqayisələr üçün qoşalaşmış ikitərəfli yükləmə kəməri; digər müqayisələr üçün qoşalaşdırılmamış iki tərəfli açılış kəməri, FDR düzəldilib. Kredit: Təbiət İnsan Davranışı (2025). DOI: 10.1038/s41562-025-02297-0
Psixoloqlar və davranış alimləri onilliklər ərzində insanların hərfləri, sözləri və cümlələri zehni olaraq necə təmsil etdiyini, kodladığını və emal etdiyini anlamağa çalışırlar. ChatGPT kimi böyük dil modellərinin (LLM) tətbiqi bu sahədə tədqiqat üçün yeni imkanlar açdı, çünki bu modellər müxtəlif insan dillərində mətnləri emal etmək və yaratmaq üçün xüsusi olaraq hazırlanmışdır.
Beləliklə, artan sayda davranış elmi və psixologiya tədqiqatları dilin kodlaşdırılması və deşifrə edilməsində iştirak edən koqnitiv proseslərə yeni işıq salmaq ümidi ilə insanların fəaliyyətini xüsusi tapşırıqlar üzrə LLM-lərin performansları ilə müqayisə etməyə başlamışdır . İnsanlar və LLM-lər mahiyyətcə fərqli olduqları üçün, hər ikisinin dili necə təmsil etdiyini real şəkildə araşdıran tapşırıqların layihələndirilməsi çətin ola bilər.
Zhejiang Universitetinin tədqiqatçıları bu yaxınlarda cümlə təmsilçiliyini öyrənmək üçün yeni bir tapşırıq hazırladılar və həm LLM-ləri, həm də insanlar üzərində sınaqdan keçirdilər. Nature Human Behavior jurnalında dərc olunmuş onların nəticələri göstərir ki, cümləni qısaltmaq istənildikdə insanlar və LLM-lər cümlələrin ifadələrində ümumi cəhətlərə işarə edərək eyni sözləri silməyə meyllidirlər.
Wei Liu, Ming Xiang və Nai Ding öz məqalələrində yazırdılar: “Cümlələrin insan beynində , eləcə də böyük dil modellərində (LLM) necə təmsil olunduğunu anlamaq koqnitiv elm üçün ciddi problem yaradır”. “İnsanların və LLM-lərin cümlələrdə ağac quruluşlu tərkib hissələrini kodlayıb kodlaşdırmadığını araşdırmaq üçün birdəfəlik öyrənmə tapşırığı hazırlayırıq.”
https://googleads.g.doubleclick.net/pagead/ads?gdpr=0&us_privacy=1—&gpp_sid=-1&client=ca-pub-0536483524803400&output=html&h=280&slotname=2793866484&adk=2520359048&adf=1100001614&pi=t.ma~as.2793866484&w=750&fwrn=4&fwrnh=0&lmt=1761133828&rafmt=1&armr=3&format=750×280&url=https%3A%2F%2Ftechxplore.com%2Fnews%2F2025-10-humans-llms-sentences-similarly.html&fwr=0&rpe=1&resp_fmts=3&wgl=1&aieuf=1&uach=WyJXaW5kb3dzIiwiMTkuMC4wIiwieDg2IiwiIiwiMTQxLjAuNzM5MC41NSIsbnVsbCwwLG51bGwsIjY0IixbWyJHb29nbGUgQ2hyb21lIiwiMTQxLjAuNzM5MC41NSJdLFsiTm90P0FfQnJhbmQiLCI4LjAuMC4wIl0sWyJDaHJvbWl1bSIsIjE0MS4wLjczOTAuNTUiXV0sMF0.&abgtt=6&dt=1761133827835&bpp=1&bdt=172&idt=68&shv=r20251020&mjsv=m202510160101&ptt=9&saldr=aa&abxe=1&cookie=ID%3Dfdc40d724f2dca57%3AT%3D1735367325%3ART%3D1761132970%3AS%3DALNI_MYStQ6fUQQQLyo5Z7z1h-XhXcWBtA&gpic=UID%3D00000f80eacffadc%3AT%3D1735367325%3ART%3D1761132970%3AS%3DALNI_MYaOugky0UawScoidzfbXof3-N-iw&eo_id_str=ID%3D878d521b85743f4c%3AT%3D1751526237%3ART%3D1761132970%3AS%3DAA-AfjZCLruwaFzoQORvGPwXS3Y2&prev_fmts=0x0&nras=1&correlator=6514970960617&frm=20&pv=1&rplot=4&u_tz=240&u_his=1&u_h=1080&u_w=1920&u_ah=1032&u_aw=1920&u_cd=24&u_sd=1&dmc=8&adx=448&ady=1820&biw=1905&bih=945&scr_x=0&scr_y=0&eid=31084127%2C31095105%2C42531705%2C95374047%2C95376002%2C95344790%2C95360684%2C95368094&oid=2&pvsid=8412771621715174&tmod=447019595&uas=0&nvt=1&ref=https%3A%2F%2Fphys.org%2F&fc=1920&brdim=0%2C0%2C0%2C0%2C1920%2C0%2C1920%2C1032%2C1920%2C945&vis=1&rsz=%7C%7CpeEbr%7C&abl=CS&pfx=0&fu=128&bc=31&plas=164x742_l%7C164x742_r&bz=1&td=1&tdf=2&psd=W251bGwsbnVsbCxudWxsLDNd&nt=1&ifi=2&uci=a!2&btvi=1&fsb=1&dtd=583
Tədqiqatlarının bir hissəsi olaraq, tədqiqatçılar ana dili Çincə danışan, doğma ingiliscə danışan və ya ikidilli (yəni həm ingilis, həm də çin dilində danışan) 372 insan iştirakçını əhatə edən bir sıra təcrübələr həyata keçirdilər. Bu iştirakçılar daha sonra ChatGPT tərəfindən tamamlanan dil tapşırığını tamamladılar.
Tapşırıq iştirakçılardan bir cümlədən bir sıra sözləri silməyi tələb edirdi. Hər bir eksperimental sınaq zamanı həm insanlara, həm də ChatGPT-yə tək nümayiş nümayiş etdirildi, sonra sözləri silərkən əməl etməli olduqları qayda barədə nəticə çıxarmalı və onu test cümləsinə tətbiq etməli oldular.
“İştirakçılardan və LLM-lərdən cümlədən hansı sözlərin silinməsi lazım olduğuna dair nəticə çıxarmaq istəndi” Liu, Xiang və Ding izah etdi. “Hər iki qrup, müvafiq olaraq, Çin və İngilis dillərinə xas olan qaydalara əməl edərək, tərkib hissəsi olmayan söz sətirlərinin əvəzinə tərkib hissələrini silməyə meyllidir.”
Maraqlıdır ki, tədqiqatçıların tapıntıları LLM-lərin daxili cümlə təmsillərinin dilçilik nəzəriyyəsi ilə uyğunlaşdığını göstərir. Onların tərtib etdiyi tapşırıqda həm insanlar, həm də ChatGPT təsadüfi söz ardıcıllıqlarından fərqli olaraq tam tərkib hissələrini (yəni, ardıcıl qrammatik vahidləri) silməyə meyllidirlər. Üstəlik, onların sildikləri söz sətirləri, dilə uyğun qaydalara riayət etməklə tapşırığı yerinə yetirdikləri dilə (yəni, Çin və ya ingiliscə) görə fərqlənirdi.
“Nəticələr yalnız söz xassələrinə və söz mövqelərinə əsaslanan modellərlə izah edilə bilməz” deyə müəlliflər yazırdılar. “Əsas odur ki, insanlar və ya LLM-lər tərəfindən silinmiş söz sətirlərinə əsaslanaraq, əsas dairə ağacı strukturu uğurla yenidən qurula bilər.”
Ümumilikdə, komandanın nəticələri göstərir ki, dili emal edərkən həm insanlar, həm də LLM-lər gizli sintaktik təsvirləri, xüsusən də ağac quruluşlu cümlə təmsillərini rəhbər tuturlar. Gələcək tədqiqatlar komandanın söz silmə tapşırığının uyğunlaşdırılmış versiyalarından və ya tamamilə yeni paradiqmalardan istifadə etməklə LLM-lərin və insanların dil təqdimat nümunələrini daha da araşdırmaq üçün bu son iş üzərində qurula bilər.
Müəllifimiz İnqrid Fadelli tərəfindən sizin üçün yazılmış , Stefani Baum tərəfindən redaktə edilmiş və Robert Eqan tərəfindən yoxlanılmış və nəzərdən keçirilmiş bu məqalə diqqətli insan əməyinin nəticəsidir. Müstəqil elmi jurnalistikanı yaşatmaq üçün sizin kimi oxuculara güvənirik. Bu hesabat sizin üçün əhəmiyyət kəsb edirsə, lütfən, ianə (xüsusilə aylıq) nəzərdən keçirin. Siz təşəkkür olaraq reklamsız hesab əldə edəcəksiniz .
Daha çox məlumat: Wei Liu et al, İnsanlarda və böyük dil modellərində gizli ağac quruluşlu cümlə təmsilinin aktiv istifadəsi, Təbiət İnsan Davranışı (2025). DOI: 10.1038/s41562-025-02297-0
Jurnal məlumatı: Nature Human Behavior
© 2025 Science X Network

