







LLM-lərə əsaslanan alqoritm məlumatların itkisiz sıxılma sürətini ikiqat artırır
İnsanlar öz elektron cihazlarında böyük miqdarda məlumat saxlayır və bu məlumatların bir hissəsini peşəkar və ya şəxsi səbəblərdən başqalarına ötürürlər. Məlumatların sıxılma üsulları beləliklə çox vacibdir, çünki onlar cihazların və kommunikasiyaların səmərəliliyini artıra bilər, istifadəçiləri bulud məlumat xidmətlərindən və xarici yaddaş qurğularından daha az etibar edir.
Mərkəzi Çin Süni İntellekt İnstitutunun, Penq Çenq Laboratoriyasının, Dalian Texnologiya Universitetinin, Çin Elmlər Akademiyasının və Vaterloo Universitetinin tədqiqatçıları bu yaxınlarda AI danışıq platforması ChatGPT-ni dəstəkləyən model kimi böyük dil modellərinə (LLM) əsaslanan yeni məlumat sıxılma yanaşması olan LMCompress-i təqdim etdilər.
Nature Machine Intelligence- də dərc olunan məqalədə qeyd olunan onların təklif etdiyi metodun klassik məlumat sıxışdırma alqoritmlərindən əhəmiyyətli dərəcədə daha güclü olduğu aşkar edilmişdir.
“2023-cü ilin yanvarında Vaterloo Universitetində Kolmoqorov mürəkkəbliyi kursunu öyrətdiyim zaman sıxılmanın başa düşülməsi fikri üzərində düşünmüşdüm” deyə məqalənin baş müəllifi Ming Li Tech Xplore-a bildirib. “Başqa sözlə, əgər bir şeyi başa düşürsənsə, onu lakonik şəkildə ifadə edə bilərsən və bir şeyi çox qısa ifadə ilə və ya bir neçə sözlə ifadə edə bilirsənsə, onu başa düşməlisən.
” Bu yazıda biz sübut etdik ki, sıxılma ən yaxşı öyrənmə/dərketmə deməkdir. Bunun əksi bu işin xəbərçisi olan digər məqalələrimizin birində sübut olundu , Google DeepMind tərəfindən hazırlanan başqa bir məqalə isə müstəqil olaraq ilkin nəticələrimizi əldə etdi.”
 və texnoloji konsepsiya (sıxılma) arasında körpü yaradır. Anlayışa əsaslanan texnologiyaların, məsələn, semantik ünsiyyətin inkişafına işıq salır. Kredit: Li et al.")
Son araşdırmalarının bir hissəsi olaraq, Li və həmkarları modellərin məlumatları nə qədər yaxşı qavrayarsa, onları daha yaxşı ümumiləşdirə və sıxışdıra bildiklərini nümayiş etdirməyə başladılar. Bu fikir 1948-ci ilə, xüsusən Klod Şennonun məşhur riyazi ünsiyyət nəzəriyyəsinə aiddir.
https://googleads.g.doubleclick.net/pagead/ads?gdpr=0&us_privacy=1—&gpp_sid=-1&client=ca-pub-0536483524803400&output=html&h=280&slotname=2793866484&adk=2520359048&adf=3042148327&pi=t.ma~as.2793866484&w=750&abgtt=6&fwrn=4&fwrnh=0&lmt=1747295532&rafmt=1&armr=3&format=750×280&url=https%3A%2F%2Ftechxplore.com%2Fnews%2F2025-05-algorithm-based-llms-lossless-compression.html&fwr=0&rpe=1&resp_fmts=3&wgl=1&uach=WyJXaW5kb3dzIiwiMTkuMC4wIiwieDg2IiwiIiwiMTM2LjAuNzEwMy45MyIsbnVsbCwwLG51bGwsIjY0IixbWyJDaHJvbWl1bSIsIjEzNi4wLjcxMDMuOTMiXSxbIkdvb2dsZSBDaHJvbWUiLCIxMzYuMC43MTAzLjkzIl0sWyJOb3QuQS9CcmFuZCIsIjk5LjAuMC4wIl1dLDBd&dt=1747295531035&bpp=1&bdt=1642&idt=713&shv=r20250513&mjsv=m202505130201&ptt=9&saldr=aa&abxe=1&cookie=ID%3Dfdc40d724f2dca57%3AT%3D1735367325%3ART%3D1747295532%3AS%3DALNI_MYStQ6fUQQQLyo5Z7z1h-XhXcWBtA&gpic=UID%3D00000f80eacffadc%3AT%3D1735367325%3ART%3D1747295532%3AS%3DALNI_MYaOugky0UawScoidzfbXof3-N-iw&eo_id_str=ID%3De43bb863646b60b8%3AT%3D1735367325%3ART%3D1747295532%3AS%3DAA-AfjbQoPwZqH28q9IwcCLRSzzg&prev_fmts=0x0%2C1905x945&nras=2&correlator=2474207635568&frm=20&pv=1&rplot=4&u_tz=240&u_his=1&u_h=1080&u_w=1920&u_ah=1032&u_aw=1920&u_cd=24&u_sd=1&dmc=8&adx=448&ady=1885&biw=1905&bih=945&scr_x=0&scr_y=0&eid=95353386%2C95360814%2C31092430%2C42533294%2C95360953%2C95356809%2C95360294&oid=2&pvsid=3384860666355507&tmod=741928462&uas=0&nvt=1&ref=https%3A%2F%2Fphys.org%2F&fc=1920&brdim=0%2C0%2C0%2C0%2C1920%2C0%2C1920%2C1032%2C1920%2C945&vis=1&rsz=%7C%7CpeEbr%7C&abl=CS&pfx=0&fu=128&bc=31&bz=1&td=1&tdf=2&psd=W251bGwsbnVsbCxudWxsLDNd&nt=1&ifi=2&uci=a!2&btvi=1&fsb=1&dtd=1738
“Şennon, mahiyyətcə, məlumatların ötürülməsini başa düşsəniz, onu sıxışdıra və ya başqa sözlə, ünsiyyət vaxtını qısalda biləcəyinizi təklif etdi” dedi Li. “80 il ərzində bu tədqiqat ideyası problemi süni intellekt və böyük dil modelləri ortaya çıxana qədər açıq qaldı. Bizim məqaləmiz mahiyyətcə təklif edir ki, əgər böyük bir dil modeli məlumatları yaxşı başa düşə bilirsə, o, bizim nə yazmağı planlaşdırdığımızı təxmin edə bilməlidir ki, bu da bizə məlumatları ən yaxşı klassik itkisiz məlumat kompressorlarından əhəmiyyətli dərəcədə yaxşı sıxışdırmağa imkan verir (məsələn, mətn üçün bzip, şəkillər üçün JPEG-2000).”
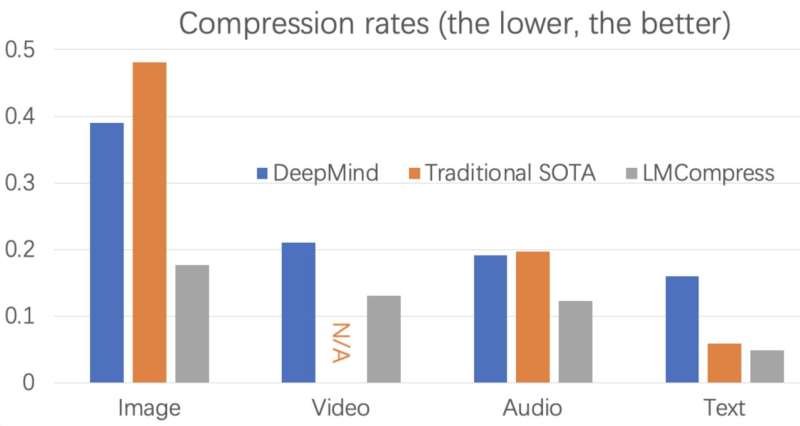
Tədqiqatçıların məlumatların sıxılma alqoritminin əsas ideyası ondan ibarətdir ki, əgər LLM istifadəçinin nə yazacağını bilirsə, o, heç bir məlumat ötürməyə ehtiyac duymur, sadəcə olaraq istifadəçinin digər tərəfdən ötürməsini istədiyini yarada bilər (yəni qəbuledicinin cihazında). Li və onların həmkarları təklif etdikləri yanaşmanı sınaqdan keçirdikdə, bunun mətnlər, şəkillər, videolar və audio faylları daxil olmaqla müxtəlif növ məlumatların sıxılma sürətini ən azı iki dəfə artırdığını tapdılar.
“Bu o mənada heyrətamizdir ki, 80 illik tədqiqatdan sonra itkisiz sıxılma alqoritmini hətta 1% təkmilləşdirsəniz, bu, artıq əlamətdardır və biz sıxılma sürətini ikiqat artıra bilmişik” dedi Li. “LMCompress böyük modellərdən (mətnlər üçün böyük dil modeli, şəkillər üçün böyük şəkil modeli və s.) istifadə edən sıxılma alqoritmidir. O, mətnləri klassik alqoritmlərdən iki dəfədən çox, şəkilləri və audioları iki dəfə, videonu isə iki dəfədən bir qədər az sıxışdırır. Buna görə də, məlumatları ötürən zaman siz təxminən iki dəfə sürətlə gedə bilərsiniz.”
Li və onun həmkarları tərəfindən hazırlanan bu son məqalə, digər tədqiqatçıları LLM-lərdən istifadə etməyə ruhlandıraraq, getdikcə daha təkmil məlumatların sıxılması üsullarının inkişafına yönəlmiş gələcək səyləri məlumatlandıra bilər. Üstəlik, komandanın LMCompress alqoritmi tezliklə daha da təkmilləşdirilə və real dünya parametrlərində tətbiq oluna bilər.
“Biz nümayiş etdirdik ki, başa düşmək sıxılmaya bərabərdir və biz bunun həlledici əhəmiyyət kəsb etdiyini düşünürük” dedi Li. “Biz həmçinin LLM-lərdən istifadə edərək məlumatların sıxılmasının yeni dövrünün yolunu açdıq. Düşünürük ki, gələcəkdə bu böyük modellər mobil telefonlarımızda və hər yerdə olduqda, məlumatları sıxışdırmaq üsulumuz klassikləri (məsələn, .zip faylları) əvəz edəcək. Növbəti araşdırmalarımızda həmçinin böyük modelləri müqayisə etmək və plagiatı aşkar etmək üçün metodologiyamızdan istifadə etməyi planlaşdırırıq.”
Daha çox məlumat: Ziguang Li və digərləri, Böyük modellər ilə məlumatların itkisiz sıxılması, Nature Machine Intelligence (2025). DOI: 10.1038/s42256-025-01033-7
Jurnal məlumatı: Nature Machine Intelligence
© 2025 Science X Network
Download QRPrint QR

