



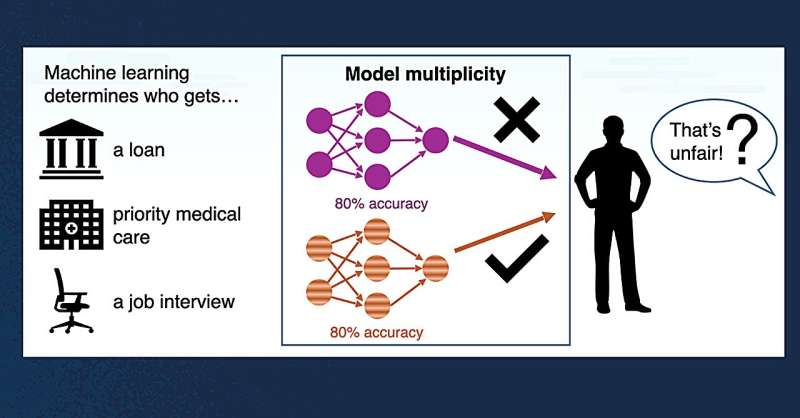
Maaşlar yüksək olduqda, maşın öyrənmə modelləri ədalətli qərarlar qəbul edirmi?
Kimberley Klementi, Kaliforniya Universiteti – San Dieqo
Lisa Lock tərəfindən redaktə edilmişdir , Andrew Zinin tərəfindən nəzərdən keçirilmişdir
Redaktorların qeydləriKredit: Kaliforniya Universiteti – San Dieqo
Maşın öyrənməsi insan-kompüter qarşılıqlı əlaqələrinin geniş spektrində yüksək riskli qərarların qəbul edilməsinin tərkib hissəsidir. İş üçün müraciət edirsiniz. Siz kredit ərizəsi təqdim edirsiniz. Alqoritmlər kimin irəlilədiyini və kimin imtina etdiyini müəyyən edir.
Kaliforniya San Dieqo və Viskonsin-Madison Universitetlərindən kompüter alimləri bu cür kritik qərarlar qəbul etmək üçün vahid maşın öyrənməsi (ML) modelindən istifadənin ümumi praktikasına meydan oxuyurlar. Onlar “eyni dərəcədə yaxşı” ML modelləri fərqli nəticələrə çatdıqda insanların necə hiss etdiklərini soruşdular.
Jacobs Mühəndislik Məktəbinin Kompüter Elmləri və Mühəndisliyi Departamenti ilə dosent Loris D’Antoni bu yaxınlarda Hesablama Sistemlərində İnsan Faktorları Konfransında ( CHI 2025 ) təqdim olunan tədqiqata rəhbərlik etmişdir. “Maşın Öyrənməsində Çoxluğun Ədalətli Təsirləri” adlı məqalədə D’Antoninin Viskonsin Universitetində işlədiyi müddətdə tədqiqatçı yoldaşları ilə başladığı və bu gün San Dieqo UC-də davam etdirilən işləri təsvir edilmişdir. O , arXiv preprint serverində mövcuddur .
D’Antoni , insan həmkarları kimi fərqli modellərin dəyişkən nəticələrə malik olduğuna dair mövcud sübutlar üzərində qurmaq üçün komanda üzvləri ilə işləmişdir . Başqa sözlə, bir yaxşı model tətbiqi rədd edə bilər, digəri isə onu təsdiqləyir. Təbii ki, bu, obyektiv qərarların necə əldə oluna biləcəyi ilə bağlı suallar doğurur.
“ML tədqiqatçıları hazırkı təcrübələrin ədalətlilik riski yaratdığını iddia edirlər. Araşdırmamız bu problemi daha dərindən araşdırdı. Biz adi maraqlı tərəflərdən və ya adi insanlardan çoxlu yüksək dəqiqlikli modellər müəyyən bir giriş üçün müxtəlif proqnozlar verdiyi zaman qərarların necə qəbul edilməli olduğunu düşündüklərini soruşduq” dedi D’Antoni.
Tədqiqat bir neçə əhəmiyyətli tapıntı üzə çıxardı. Birincisi, maraqlı tərəflər, xüsusən də birdən çox model razılaşmırsa, standart bir modelə əsaslanan təcrübədən imtina etdilər. İkincisi, iştirakçılar belə hallarda qərarların təsadüfi olması fikrini rədd etdilər.
“Biz bu nəticələri maraqlı hesab edirik, çünki bu üstünlüklər ML inkişafında standart təcrübə və ədalətli təcrübələr üzrə fəlsəfə tədqiqatı ilə ziddiyyət təşkil edir” dedi birinci müəllif və Ph.D. Viskonsin Universitetində D’Antoni tərəfindən məsləhət görülən və payızda Carlton Kollecində dosent vəzifəsinə başlayacaq tələbə Anna Meyer.
Komanda ümid edir ki, bu anlayışlar gələcək modelin inkişafı və siyasətini istiqamətləndirəcək. Əsas tövsiyələrə bir sıra modellər üzrə axtarışların genişləndirilməsi və fikir ayrılıqlarını həll etmək üçün insan qərarlarının qəbul edilməsini həyata keçirmək daxildir – xüsusən də yüksək riskli şəraitdə.
Tədqiqat qrupunun digər üzvləri arasında Viskonsin Universitetinin kompüter elmləri üzrə dosenti Aws Albarghouthi və Apple-dan Yea-Seul Kim var.
Daha çox məlumat: Anna P. Meyer və digərləri, Maşın Öyrənməsində Çoxluğun Ədalətli Təsirlərinin Qavramaları, arXiv (2024). DOI: 10.48550/arxiv.2409.12332
Jurnal məlumatı: arXiv Kaliforniya Universiteti – San Dieqo tərəfindən təmin edilmişdir