



Ortada itdi: LLM arxitekturası və təlim məlumatları süni intellektin mövqeyini necə formalaşdırır
Tədqiqatlar göstərdi ki, böyük dil modelləri (LLM) sənədin və ya söhbətin əvvəlində və sonunda məlumatı həddindən artıq vurğulayır, ortasına isə əhəmiyyət vermir.
Bu “mövqe qərəzliliyi” o deməkdir ki, əgər vəkil 30 səhifəlik ifadədə müəyyən ifadəni əldə etmək üçün LLM ilə işləyən virtual köməkçidən istifadə edirsə, LLM ilkin və ya son səhifələrdə olarsa, düzgün mətni tapmaq ehtimalı daha yüksəkdir.
MIT tədqiqatçıları bu fenomenin arxasındakı mexanizmi kəşf ediblər.
Onlar LLM-lərin əsasını təşkil edən maşın öyrənmə arxitekturası vasitəsilə məlumatın necə axdığını öyrənmək üçün nəzəri çərçivə yaratdılar . Onlar tapdılar ki, modelin giriş məlumatlarını necə emal etdiyinə nəzarət edən müəyyən dizayn seçimləri mövqe meylinə səbəb ola bilər.
Onların təcrübələri göstərdi ki, model arxitekturaları, xüsusən də məlumatın model daxilində daxil olan sözlər arasında yayılmasına təsir edənlər mövqe meylinə səbəb ola və ya gücləndirə bilər və təlim məlumatları da problemə kömək edir.
Əsər arXiv preprint serverində dərc olunur .
Mövqe qərəzinin mənşəyini dəqiq müəyyənləşdirməklə yanaşı, onların çərçivəsi gələcək model dizaynlarında diaqnoz qoymaq və düzəltmək üçün istifadə edilə bilər.
Bu, uzun söhbətlər zamanı mövzuda qalan daha etibarlı chatbotlara, çoxlu xəstə məlumatlarını idarə edərkən daha ədalətli düşünən tibbi AI sistemlərinə və proqramın bütün hissələrinə daha çox diqqət yetirən kod köməkçilərinə səbəb ola bilər.
“Bu modellər qara qutulardır , ona görə də bir LLM istifadəçisi olaraq, siz yəqin ki, bilmirsiniz ki, mövqe meylinin modelinizin uyğunsuzluğuna səbəb ola bilər. Siz sadəcə sənədlərinizi istədiyiniz qaydada verirsiniz və onun işləməsini gözləyirsiniz. Lakin bu qara qutu modellərinin əsas mexanizmini daha yaxşı başa düşərək, biz bu məhdudiyyətləri aradan qaldırmaqla onları təkmilləşdirə bilərik”, – MIT-in Data İnstitutunun tələbəsi Xinyi Wu deyir. (IDSS) və İnformasiya və Qərar Sistemləri Laboratoriyası (LIDS) və məqalənin ilk müəllifidir.
Onun həmmüəllifləri arasında MIT postdoc-u Yifei Wang; və baş müəlliflər Stefanie Jegelka, elektrik mühəndisliyi və kompüter elmləri (EECS) dosenti və IDSS və Kompüter Elmləri və Süni İntellekt Laboratoriyasının (CSAIL) üzvü; və Əli Jadbabaie, professor və İnşaat və Ətraf Mühit Mühəndisliyi Departamentinin rəhbəri, IDSS-nin əsas professor-müəllim heyəti və LIDS-in əsas tədqiqatçısı. Tədqiqat Maşın Öyrənməsi üzrə Beynəlxalq Konfransda təqdim olunacaq.
https://googleads.g.doubleclick.net/pagead/ads?gdpr=0&us_privacy=1—&gpp_sid=-1&client=ca-pub-0536483524803400&output=html&h=280&slotname=2793866484&adk=2520359048&adf=1100001614&pi=t.ma~as.2793866484&w=750&abgtt=6&fwrn=4&fwrnh=0&lmt=1750223362&rafmt=1&armr=3&format=750×280&url=https%3A%2F%2Ftechxplore.com%2Fnews%2F2025-06-lost-middle-llm-architecture-ai.html&fwr=0&rpe=1&resp_fmts=3&wgl=1&uach=WyJXaW5kb3dzIiwiMTkuMC4wIiwieDg2IiwiIiwiMTM3LjAuNzE1MS4xMDQiLG51bGwsMCxudWxsLCI2NCIsW1siR29vZ2xlIENocm9tZSIsIjEzNy4wLjcxNTEuMTA0Il0sWyJDaHJvbWl1bSIsIjEzNy4wLjcxNTEuMTA0Il0sWyJOb3QvQSlCcmFuZCIsIjI0LjAuMC4wIl1dLDBd&dt=1750223361359&bpp=16&bdt=198&idt=107&shv=r20250616&mjsv=m202506160101&ptt=9&saldr=aa&abxe=1&cookie=ID%3Dfdc40d724f2dca57%3AT%3D1735367325%3ART%3D1750223138%3AS%3DALNI_MYStQ6fUQQQLyo5Z7z1h-XhXcWBtA&gpic=UID%3D00000f80eacffadc%3AT%3D1735367325%3ART%3D1750223138%3AS%3DALNI_MYaOugky0UawScoidzfbXof3-N-iw&eo_id_str=ID%3De43bb863646b60b8%3AT%3D1735367325%3ART%3D1750223138%3AS%3DAA-AfjbQoPwZqH28q9IwcCLRSzzg&prev_fmts=0x0&nras=1&correlator=5514743934493&frm=20&pv=1&rplot=4&u_tz=240&u_his=1&u_h=1080&u_w=1920&u_ah=1032&u_aw=1920&u_cd=24&u_sd=1&dmc=8&adx=448&ady=2137&biw=1905&bih=945&scr_x=0&scr_y=0&eid=42532523%2C95353386%2C95362435%2C95362656%2C31093017%2C95362798%2C95359266%2C95362805%2C95363070%2C95360684&oid=2&pvsid=8019599786984891&tmod=1364553759&uas=0&nvt=1&ref=https%3A%2F%2Fphys.org%2F&fc=1920&brdim=0%2C0%2C0%2C0%2C1920%2C0%2C1920%2C1032%2C1920%2C945&vis=1&rsz=%7C%7CpeEbr%7C&abl=CS&pfx=0&fu=128&bc=31&bz=1&td=1&tdf=2&psd=W251bGwsbnVsbCxudWxsLDNd&nt=1&ifi=2&uci=a!2&btvi=1&fsb=1&dtd=1044
Diqqəti təhlil etmək
Claude, Llama və GPT-4 kimi LLM-lər transformator kimi tanınan bir növ neyron şəbəkəsi arxitekturası ilə təchiz edilmişdir. Transformatorlar ardıcıl məlumatları emal etmək, bir cümləni token adlanan hissələrə kodlaşdırmaq və sonra hansı sözlərin gələcəklərini proqnozlaşdırmaq üçün tokenlər arasındakı əlaqələri öyrənmək üçün nəzərdə tutulmuşdur.
Bu modellər, tokenlərin seçici olaraq əlaqəli tokenlərə diqqət yetirməsinə və ya iştirak etməsinə imkan verməklə kontekstdə məna yaratmaq üçün məlumat emalı qovşaqlarının bir-birinə bağlı təbəqələrindən istifadə edən diqqət mexanizmi sayəsində çox yaxşı nəticə əldə etdilər.
Ancaq hər bir token 30 səhifəlik sənəddə hər bir digər tokenə qoşula bilsə, bu, tez bir zamanda hesablama baxımından çətin olur. Beləliklə, mühəndislər transformator modelləri qurarkən, tez-tez işarənin iştirak edə biləcəyi sözləri məhdudlaşdıran diqqəti maskalama üsullarından istifadə edirlər. Məsələn, səbəb maskası yalnız sözlərin özündən əvvəl gələnlərə diqqət yetirməsinə imkan verir.
Mühəndislər həmçinin modelə cümlədəki hər sözün yerini anlamağa kömək etmək üçün mövqe kodlaşdırmalarından istifadə edir və performansını artırır.
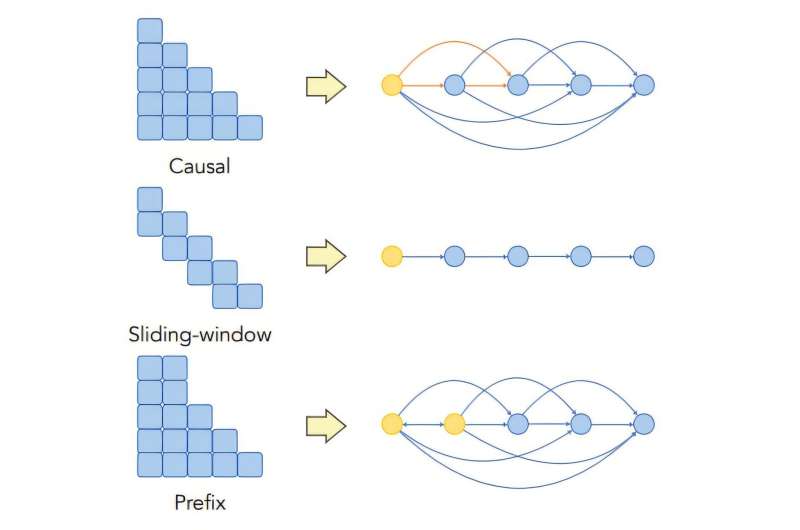
MIT tədqiqatçıları bu modelləşdirmə seçimlərinin, diqqət maskalarının və mövqe kodlaşdırmalarının mövqe meylinə necə təsir edə biləcəyini araşdırmaq üçün qrafik əsaslı nəzəri çərçivə qurdular.
Vu deyir: “Hər şey diqqət mexanizmində birləşir və dolaşıqdır, ona görə də onu öyrənmək çox çətindir. Qrafiklər diqqət mexanizmindəki sözlər arasındakı asılı əlaqəni təsvir etmək və onları bir neçə təbəqədə izləmək üçün çevik bir dildir”.
Onların nəzəri təhlili göstərdi ki, səbəbli maskalanma modelə girişin başlanğıcına xas olan qərəz verir, hətta məlumatlarda bu qərəz yoxdur.
Əgər əvvəlki sözlər cümlənin mənası üçün nisbətən əhəmiyyətsizdirsə, səbəb-nəticə maskalanması hər halda transformatorun başlanğıcına daha çox diqqət yetirməsinə səbəb ola bilər.
“Cümlədəki əvvəlki sözlərin və sonrakı sözlərin daha vacib olduğu çox vaxt doğru olsa da, LLM təbii dil yaratmayan bir vəzifədə, məsələn sıralama və ya məlumat axtarışında istifadə olunarsa, bu qərəzlər son dərəcə zərərli ola bilər” dedi Wu.
Model böyüdükcə əlavə diqqət mexanizmi ilə bu qərəzlik gücləndirilir, çünki girişin əvvəlki hissələri modelin əsaslandırma prosesində daha tez-tez istifadə olunur.
Onlar həmçinin tapdılar ki, sözləri yaxınlıqdakı sözlərlə daha güclü şəkildə əlaqələndirmək üçün mövqe kodlaşdırmalarından istifadə mövqe meylini azalda bilər. Texnika modelin diqqətini lazımi yerə yönəldir, lakin onun təsiri daha çox diqqət təbəqəsi olan modellərdə sulandırıla bilər. Bu dizayn seçimləri mövqe qərəzinin yalnız bir səbəbidir – bəziləri ardıcıllıqla sözlərin prioritetləşdirilməsini öyrənmək üçün modelin istifadə etdiyi təlim məlumatlarından əldə edilə bilər.
“Məlumatlarınızın müəyyən bir şəkildə qərəzli olduğunu bilirsinizsə, o zaman modelləşdirmə seçimlərinizi tənzimləməklə yanaşı, modelinizi də dəqiqləşdirməlisiniz” dedi Wu.
Ortada itdi
Nəzəri çərçivə qurduqdan sonra tədqiqatçılar məlumat axtarışı tapşırığı üçün mətn ardıcıllığında düzgün cavabın mövqeyini sistematik olaraq dəyişdirdikləri təcrübələr həyata keçirdilər.
Təcrübələr “ortada itən” fenomeni göstərdi, burada axtarış dəqiqliyi U formalı bir nümunəyə əməl etdi. Düzgün cavab ardıcıllığın əvvəlində olsaydı, modellər ən yaxşı nəticə göstərdi. Düzgün cavab sona yaxın olarsa, performans bir az geriləmədən əvvəl ortaya yaxınlaşdıqca azaldı.
Nəhayət, onların işi göstərir ki, fərqli maskalanma texnikasından istifadə etmək, diqqət mexanizmindən əlavə təbəqələri silmək və ya strateji olaraq mövqe kodlaşdırmalarından istifadə etmək mövqe meylini azalda və modelin dəqiqliyini artıra bilər.
“Nəzəriyyə və eksperimentlərin birləşməsini həyata keçirərək, biz o zaman aydın olmayan model dizayn seçimlərinin nəticələrini nəzərdən keçirə bildik. Əgər modeldən yüksək riskli tətbiqlərdə istifadə etmək istəyirsinizsə, onun nə vaxt işləyəcəyini, nə vaxt işləməyəcəyini və nə üçün olduğunu bilməlisiniz,” Jadbabaie deyir.
Gələcəkdə tədqiqatçılar mövqe kodlaşdırmalarının təsirlərini daha da araşdırmaq və müəyyən tətbiqlərdə mövqe qərəzinin necə strateji şəkildə istifadə oluna biləcəyini öyrənmək istəyirlər.
“Bu tədqiqatçılar transformator modelinin mərkəzində olan diqqət mexanizminə nadir nəzəri obyektiv təklif edirlər. Onlar transformator davranışında uzun müddətdir davam edən qəribəlikləri aydınlaşdıran, diqqət mexanizmlərinin, xüsusən də səbəb maskaları ilə, modellərin ardıcıllığın başlanğıcına doğru meyl etdiyini göstərən cəlbedici təhlil təqdim edirlər . Məqalə hər iki dünyanın ən yaxşısına nail olur – riyazi aydınlıq baxımından əldə edilən riyazi aydınlıqlar. real dünya sistemləri “dedi, professor və Stenford Universitetinin Hesablama Bazarının Dizayn Mərkəzinin direktoru, bu işlə məşğul olmayan Amin Saberi.
Daha çox məlumat: Xinyi Wu et al, On the Eergence of Position Bias in Transformers, arXiv (2025). DOI: 10.48550/arxiv.2502.01951
Jurnal məlumatı: arXiv Massaçusets Texnologiya İnstitutu tərəfindən təmin edilmişdir