



Problemlər üzərində düşünməyi özünə öyrədən AI modeli, heç bir insan tələb etmir
Paul Arnold tərəfindən , Phys.org
Lisa Lock tərəfindən redaktə edilmiş , Robert Eqan tərəfindən nəzərdən keçirilmişdir
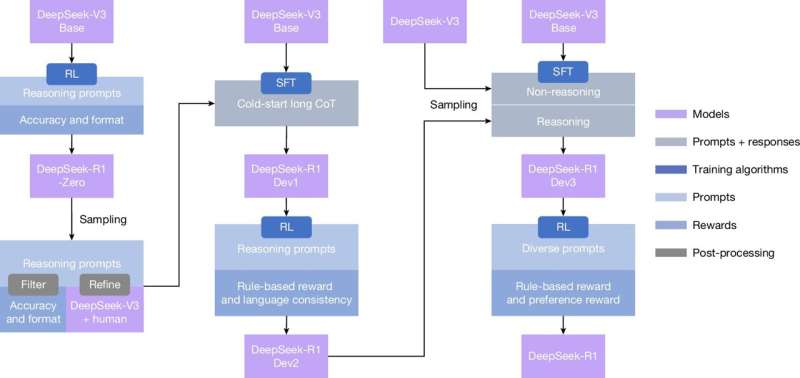
Redaktorların qeydləriDeepSeek-R1-in çoxmərhələli boru kəməri. Kredit: Təbiət (2025). DOI: 10.1038/s41586-025-09422-z
Süni intellekt hər gün daha da ağıllılaşır, amma yenə də öz sərhədləri var. Ən böyük problemlərdən biri qabaqcıl AI modellərinə düşünməyi öyrətməkdir, bu da problemlərin addım-addım həll edilməsi deməkdir. Lakin “Nature” jurnalında dərc olunan yeni məqalədə Çinin süni intellekt şirkəti DeepSeek AI komandası bildirir ki, onlar öz R1 modellərini insan müdaxiləsi olmadan özbaşına düşünməyi öyrədə biliblər.
Bir çoxumuz problemi həll etməyə çalışanda adətən cavabı dərhal almırıq. Biz həll yoluna çatana qədər məlumat toplamaq və qeydlər aparmağı əhatə edən metodik prosesə əməl edirik. Ənənəvi olaraq, süni intellekt modellərini düşünmək üçün öyrətmək bizim yanaşmamızı kopyalamaqdan ibarətdir. Bununla belə, insanların süni intellekt modelinə problemin həlli ilə bağlı saysız-hesabsız nümunələr göstərdiyi uzun, uzanan bir prosesdir. Bu, həm də o deməkdir ki, AI yalnız verilmiş nümunələr qədər yaxşıdır və insan qərəzlərini qəbul edə bilər.
DeepSeek AI-də tədqiqatçılar R1 modelini hər addımda göstərmək əvəzinə, gücləndirici öyrənmə adlı texnikadan istifadə etdilər. Düzgün cavablar üçün mükafatlardan istifadə edən bu sınaq və səhv yanaşması modeli özü üçün düşünməyə təşviq etdi.
“Modelə problemi necə həll edəcəyini açıq şəkildə öyrətmək əvəzinə, biz onu sadəcə olaraq düzgün stimullarla təmin edirik və o, təkmil problemin həlli strategiyalarını müstəqil şəkildə inkişaf etdirir” deyə tədqiqatçılar öz məqalələrində yazırlar.
DeepSeek-in R1 modeli çətin riyaziyyat, kodlaşdırma və elm problemləri üzrə təlim keçmişdir. Aldığı yeganə mükafat onun son cavabının doğru olduğuna dair bir siqnal idi. Təlim zamanı tədqiqatçılar onun öz işini yoxlamaq və həll yolu tapmaq üçün müxtəlif strategiyaları araşdırmaq kimi bacarıqları inkişaf etdirdiyini gördülər. Hətta öz düşüncə prosesini əks etdirən “gözlə” kimi sözlərdən istifadə etməyə başladı. Əgər yol düzgün cavaba gətirib çıxardısa, o strategiya gücləndirildi. Səhv idisə, model bunu təkrarlamamağı öyrəndi. Bəzi insan müdaxiləsi var idi , ancaq prosesdə yalnız R1-in bacarıqlarını cilalamaq üçün.Təlim prosesi boyunca DeepSeek-R1-Zero dəqiqliyi və çıxış uzunluğu. Kredit: Təbiət (2025). DOI: 10.1038/s41586-025-09422-z
Nəticələr təsir edici idi. R1 riyaziyyat, kodlaşdırma və elm tapşırıqlarında insan rəhbərliyi ilə öyrədilmiş köhnə modellərdən daha yaxşı çıxış etdi. Ən diqqətəlayiq nəticələrdən biri onun ən ağıllı orta məktəb şagirdləri üçün çətin riyaziyyat yarışması olan American Invitational Mathematics Examination (AIME) 2024-də 86,7% dəqiqliyə nail olması idi.
Hətta bu görkəmli nəticələrə baxmayaraq, tədqiqatçılar modellərinin üzərində işləmək üçün bəzi məhdudiyyətlərin olduğunu etiraf edirlər. Məsələn, bəzən qeyri-ingiliscə göstəriş verildikdə dilləri qarışdırır və bəzi sadə problemləri lazım olduğundan daha mürəkkəbləşdirirdi. Lakin bu problemlər aradan qaldırıldıqdan sonra tədqiqatçılar hesab edirlər ki, özünü əsaslandıra bilən süni intellekt modeli daha bacarıqlı və avtonom modellərin yeni erasına gətirib çıxaracaq.
Müəllifimiz Pol Arnold tərəfindən sizin üçün yazılmış , Lisa Lok tərəfindən redaktə edilmiş və Robert Eqan tərəfindən yoxlanılmış və nəzərdən keçirilmiş bu məqalə diqqətli insan əməyinin nəticəsidir. Müstəqil elmi jurnalistikanı yaşatmaq üçün sizin kimi oxuculara güvənirik. Bu hesabat sizin üçün əhəmiyyət kəsb edirsə, lütfən, ianə (xüsusilə aylıq) nəzərdən keçirin. Siz təşəkkür olaraq reklamsız hesab əldə edəcəksiniz .
Daha çox məlumat: Daya Guo və digərləri, DeepSeek-R1 gücləndirici öyrənmə vasitəsilə LLM-lərdə düşünməyi təşviq edir, Təbiət (2025). DOI: 10.1038/s41586-025-09422-z
Jurnal məlumatı: Təbiət
© 2025 Science X Network