







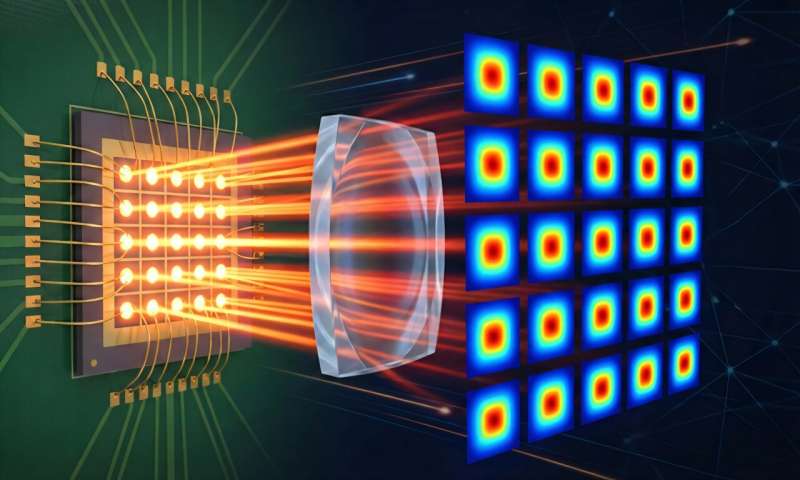



Süni intellekt insan müdaxiləsi olmadan görmə və səsin necə əlaqəli olduğunu öyrənir
İnsanlar təbii olaraq görmə və səs arasında əlaqə quraraq öyrənirlər. Məsələn, kiminsə violonçel çalmasını seyr edə bilərik və onun hərəkətlərinin eşitdiyimiz musiqini yaratdığını anlaya bilərik.
MIT və başqa yerlərdən olan tədqiqatçılar tərəfindən hazırlanmış yeni yanaşma süni intellekt modelinin eyni şəkildə öyrənmə qabiliyyətini yaxşılaşdırır. Bu, jurnalistika və film istehsalı kimi tətbiqlərdə faydalı ola bilər, burada model avtomatik video və audio axtarışı vasitəsilə multimodal məzmunun seçilməsinə kömək edə bilər.
Uzunmüddətli perspektivdə, bu iş robotun eşitmə və vizual məlumatların çox vaxt sıx əlaqəli olduğu real dünya mühitlərini anlamaq qabiliyyətini artırmaq üçün istifadə edilə bilər.
Qruplarının əvvəlki işlərini təkmilləşdirərək, tədqiqatçılar maşın öyrənmə modellərinə insan etiketlərinə ehtiyac olmadan video kliplərdən müvafiq audio və vizual məlumatların uyğunlaşdırılmasına kömək edən bir üsul yaratdılar.
Onlar orijinal modellərinin necə öyrədildiyini tənzimlədilər ki, o, müəyyən bir video çərçivə ilə həmin anda baş verən audio arasında daha incə yazışmaları öyrənsin. Tədqiqatçılar həmçinin sistemin iki fərqli öyrənmə məqsədini tarazlaşdırmağa kömək edən bəzi memarlıq tənzimləmələri də ediblər ki, bu da performansı artırır.
Birlikdə götürdükdə, bu nisbətən sadə təkmilləşdirmələr video axtarış tapşırıqlarında və audiovizual səhnələrdə hərəkətin təsnifatında yanaşmanın dəqiqliyini artırır. Məsələn, yeni üsul avtomatik və dəqiq bir şəkildə çırpılan qapının səsi ilə videoklipdə onun bağlanması vizualını uyğunlaşdıra bilər.
https://googleads.g.doubleclick.net/pagead/ads?gdpr=0&us_privacy=1—&gpp_sid=-1&client=ca-pub-0536483524803400&output=html&h=280&slotname=2793866484&adk=161300458&adf=1100001614&pi=t.ma~as.2793866484&w=540&abgtt=6&fwrn=4&fwrnh=0&lmt=1747930524&rafmt=1&armr=3&format=540×280&url=https%3A%2F%2Ftechxplore.com%2Fnews%2F2025-05-ai-vision-human-intervention.html&fwr=0&rpe=1&resp_fmts=3&wgl=1&uach=WyJXaW5kb3dzIiwiMTkuMC4wIiwieDg2IiwiIiwiMTM2LjAuNzEwMy4xMTQiLG51bGwsMCxudWxsLCI2NCIsW1siQ2hyb21pdW0iLCIxMzYuMC43MTAzLjExNCJdLFsiR29vZ2xlIENocm9tZSIsIjEzNi4wLjcxMDMuMTE0Il0sWyJOb3QuQS9CcmFuZCIsIjk5LjAuMC4wIl1dLDBd&dt=1747930523990&bpp=1&bdt=176&idt=107&shv=r20250520&mjsv=m202505190101&ptt=9&saldr=aa&abxe=1&cookie=ID%3D594147a00c618f4c%3AT%3D1735548631%3ART%3D1747930029%3AS%3DALNI_MYbuCvlfveSCnpeUIQKyQ2DBT11fQ&gpic=UID%3D00000f84124e2904%3AT%3D1735548631%3ART%3D1747930029%3AS%3DALNI_Maf8g334ShSARz9IhljaNTJv-vUzg&eo_id_str=ID%3D639b28d7655b7aa4%3AT%3D1735548631%3ART%3D1747930029%3AS%3DAA-Afjakj_-HiAALGKSfOxRJbP3s&prev_fmts=0x0&nras=1&correlator=2109091112160&frm=20&pv=1&rplot=4&u_tz=240&u_his=1&u_h=864&u_w=1536&u_ah=816&u_aw=1536&u_cd=24&u_sd=1.25&dmc=8&adx=395&ady=1676&biw=1521&bih=730&scr_x=0&scr_y=0&eid=95353386%2C95344789%2C95361624%2C95360953%2C95360294&oid=2&pvsid=2201600662063102&tmod=1683891193&uas=0&nvt=1&ref=https%3A%2F%2Fphys.org%2F&fc=1920&brdim=0%2C0%2C0%2C0%2C1536%2C0%2C1536%2C816%2C1536%2C730&vis=1&rsz=%7C%7CpeEbr%7C&abl=CS&pfx=0&fu=128&bc=31&bz=1&td=1&tdf=2&psd=W251bGwsbnVsbCxudWxsLDNd&nt=1&ifi=2&uci=a!2&btvi=1&fsb=1&dtd=301
“Biz həm audio, həm də vizual məlumatın bir anda daxil olması və hər iki üsulu qüsursuz şəkildə emal etmək baxımından insanlar kimi dünyanı emal edə bilən süni intellekt sistemləri qururuq .
MIT aspirantı və arXiv preprint serverində dərc edilmiş bu tədqiqatla bağlı məqalənin həmmüəllifi Endryu Rouditçenko deyir: “Gözləyirik ki, bu audio-vizual texnologiyanı gündəlik istifadə etdiyimiz bəzi alətlərə, məsələn, böyük dil modellərinə inteqrasiya edə bilsək , bu , çoxlu yeni proqramlar aça bilər”.
Kağızda ona Almaniyanın Höte Universitetinin aspirantı, aparıcı müəllif Edson Araujo da qoşulur; Yuan Gong, keçmiş MIT postdoc; Saurabhchand Bhati, indiki MIT postdok; Samuel Thomas, Brian Kingsbury və Leonid Karlinsky IBM Research; Rogerio Feris, MIT-IBM Watson AI Laboratoriyasının baş alimi və meneceri; James Glass, böyük tədqiqatçı alim və MIT Kompüter Elmləri və Süni İntellekt Laboratoriyasının (CSAIL) Danışıq Dil Sistemləri Qrupunun rəhbəri; və baş müəllif Hilde Kuehne, Höte Universitetinin kompüter elmləri professoru və MIT-IBM Watson AI Laboratoriyasının əlaqəli professoru.
Əsər 11-15 iyun tarixlərində Nashville şəhərində keçiriləcək Kompüter Görünüşü və Pattern Tanınması Konfransında ( CVPR 2025 ) təqdim olunacaq.
Sinxronizasiya edilir
Bu iş tədqiqatçıların bir neçə il əvvəl inkişaf etdirdiyi maşın öyrənmə metoduna əsaslanır və bu, insan etiketlərinə ehtiyac olmadan audio və vizual məlumatları eyni vaxtda emal etmək üçün multimodal modeli öyrətmək üçün səmərəli yol təqdim edir.
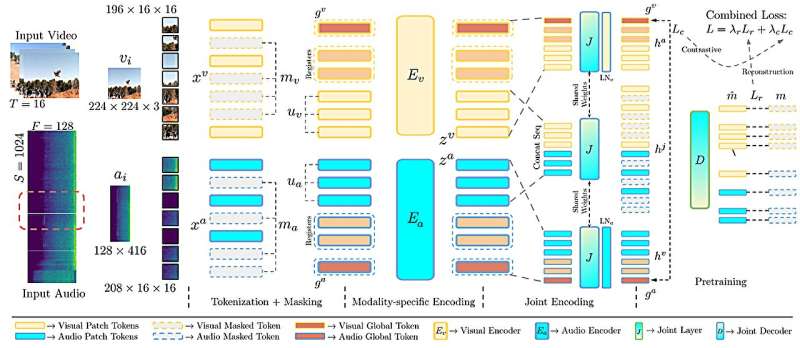
Tədqiqatçılar CAV-MAE adlanan bu modeli etiketlənməmiş video kliplər ilə qidalandırır və o, vizual və audio məlumatları ayrı-ayrılıqda token adlanan təsvirlərə kodlayır. Qeydiyyatdan alınan təbii səsdən istifadə edərək, model avtomatik olaraq daxili təmsil məkanında bir-birinə yaxın olan müvafiq audio və vizual nişanlar cütlərini xəritələməyi öyrənir.
Onlar aşkar ediblər ki, iki öyrənmə məqsədindən istifadə modelin öyrənmə prosesini balanslaşdırır və bu, CAV-MAE-yə müvafiq audio və vizual məlumatları anlamağa imkan verir, eyni zamanda istifadəçi sorğularına uyğun gələn video klipləri bərpa etmək qabiliyyətini artırır.
Lakin CAV-MAE audio və vizual nümunələri bir vahid kimi qəbul edir, beləliklə, 10 saniyəlik video klip və qapının çırpılması səsi, hətta bu audio hadisə videonun yalnız bir saniyəsində baş versə belə, bir-birinə uyğunlaşdırılır.
CAV-MAE Sync adlanan təkmilləşdirilmiş modelində tədqiqatçılar, model verilənlərin təqdimatını hesablamazdan əvvəl audionu daha kiçik pəncərələrə ayırdılar, beləliklə, o, hər bir kiçik audio pəncərəsinə uyğun gələn ayrı-ayrı təqdimatlar yaradır.
Təlim zamanı model bir video kadrı məhz həmin kadr zamanı baş verən audio ilə əlaqələndirməyi öyrənir.
“Bunu etməklə, model daha incə yazışma öyrənir ki, bu da sonradan bu məlumatları birləşdirəndə performansa kömək edir” dedi Araujo.
Onlar həmçinin modelin iki öyrənmə məqsədini balanslaşdırmağa kömək edən memarlıq təkmilləşdirmələrini də daxil etdilər.
https://googleads.g.doubleclick.net/pagead/ads?gdpr=0&us_privacy=1—&gpp_sid=-1&client=ca-pub-0536483524803400&output=html&h=280&slotname=2793866484&adk=161300458&adf=2636419947&pi=t.ma~as.2793866484&w=540&abgtt=6&fwrn=4&fwrnh=0&lmt=1747930524&rafmt=1&armr=3&format=540×280&url=https%3A%2F%2Ftechxplore.com%2Fnews%2F2025-05-ai-vision-human-intervention.html&fwr=0&rpe=1&resp_fmts=3&wgl=1&uach=WyJXaW5kb3dzIiwiMTkuMC4wIiwieDg2IiwiIiwiMTM2LjAuNzEwMy4xMTQiLG51bGwsMCxudWxsLCI2NCIsW1siQ2hyb21pdW0iLCIxMzYuMC43MTAzLjExNCJdLFsiR29vZ2xlIENocm9tZSIsIjEzNi4wLjcxMDMuMTE0Il0sWyJOb3QuQS9CcmFuZCIsIjk5LjAuMC4wIl1dLDBd&dt=1747930523990&bpp=1&bdt=176&idt=184&shv=r20250520&mjsv=m202505190101&ptt=9&saldr=aa&abxe=1&cookie=ID%3D594147a00c618f4c%3AT%3D1735548631%3ART%3D1747930029%3AS%3DALNI_MYbuCvlfveSCnpeUIQKyQ2DBT11fQ&gpic=UID%3D00000f84124e2904%3AT%3D1735548631%3ART%3D1747930029%3AS%3DALNI_Maf8g334ShSARz9IhljaNTJv-vUzg&eo_id_str=ID%3D639b28d7655b7aa4%3AT%3D1735548631%3ART%3D1747930029%3AS%3DAA-Afjakj_-HiAALGKSfOxRJbP3s&prev_fmts=0x0%2C540x280&nras=1&correlator=2109091112160&frm=20&pv=1&rplot=4&u_tz=240&u_his=1&u_h=864&u_w=1536&u_ah=816&u_aw=1536&u_cd=24&u_sd=1.25&dmc=8&adx=395&ady=3531&biw=1521&bih=730&scr_x=0&scr_y=0&eid=95353386%2C95344789%2C95361624%2C95360953%2C95360294&oid=2&pvsid=2201600662063102&tmod=1683891193&uas=0&nvt=1&ref=https%3A%2F%2Fphys.org%2F&fc=1920&brdim=0%2C0%2C0%2C0%2C1536%2C0%2C1536%2C816%2C1536%2C730&vis=1&rsz=%7C%7CpeEbr%7C&abl=CS&pfx=0&fu=128&bc=31&bz=1&td=1&tdf=2&psd=W251bGwsbnVsbCxudWxsLDNd&nt=1&ifi=3&uci=a!3&btvi=2&fsb=1&dtd=306
‘Dəyişmə otağı’ əlavə edilir
Model oxşar audio və vizual məlumatları əlaqələndirməyi öyrəndiyi təzadlı məqsədi və istifadəçi sorğuları əsasında xüsusi audio və vizual məlumatların bərpasını hədəfləyən yenidənqurma məqsədini özündə birləşdirir.
CAV-MAE Sync-də tədqiqatçılar modelin öyrənmə qabiliyyətini təkmilləşdirmək üçün iki yeni növ məlumat təqdimatı və ya token təqdim etdilər.
Onlara təzadlı öyrənmə məqsədi ilə kömək edən xüsusi “qlobal tokenlər” və modelin yenidənqurma məqsədi üçün vacib detallara diqqət yetirməsinə kömək edən xüsusi “qeydiyyat nişanları” daxildir.
“Əsasən, biz modelə bir az daha çox əyilmə otağı əlavə edirik ki, o, bu iki tapşırığın hər birini, təzadlı və rekonstruktiv, bir az daha müstəqil şəkildə yerinə yetirə bilsin. Bu, ümumi performansdan faydalandı”, – Araujo əlavə edir.
Tədqiqatçıların bu təkmilləşdirmələrin CAV-MAE Sync-in performansını yaxşılaşdıracağına dair bəzi intuisiyaları olsa da, modeli istədikləri istiqamətə dəyişdirmək üçün ehtiyatlı strategiya kombinasiyası lazım idi.
Rouditçenko deyir: “Çünki bizim çoxlu modallıqlarımız var, hər iki modallıq üçün yaxşı bir modelə ehtiyacımız var, lakin biz də onları birləşdirib əməkdaşlıq etmələrini təmin etməliyik”.
Nəhayət, onların təkmilləşdirmələri modelin audio sorğu əsasında videoları əldə etmək və it hürən və ya çalan alət kimi audiovizual səhnənin sinfini proqnozlaşdırmaq qabiliyyətini təkmilləşdirdi.
Onun nəticələri əvvəlki işlərindən daha dəqiq idi və o, həmçinin daha böyük həcmdə təlim məlumatı tələb edən daha mürəkkəb, ən müasir metodlardan daha yaxşı çıxış etdi.
Araujo deyir: “Bəzən çox sadə ideyalar və ya verilənlərdə gördüyünüz kiçik nümunələr üzərində işlədiyiniz modelin üzərinə tətbiq edildikdə böyük dəyərə malikdir”.
Gələcəkdə tədqiqatçılar performansı yaxşılaşdıra bilən CAV-MAE Sync-ə daha yaxşı məlumat təqdimatı yaradan yeni modelləri daxil etmək istəyirlər. Onlar həmçinin sistemlərinə mətn məlumatlarını idarə etməyə imkan vermək istəyirlər ki, bu da audiovizual böyük dil modelinin yaradılması istiqamətində mühüm addım olardı.
Ətraflı məlumat: Edson Araujo et al, CAV-MAE Sinxronizasiyası: Fine-grained Alignment vasitəsilə Kontrastiv Audio-Visual Maska Avtokoderlərinin təkmilləşdirilməsi, arXiv (2025). DOI: 10.48550/arxiv.2505.01237
Jurnal məlumatı: arXiv Massaçusets Texnologiya İnstitutu tərəfindən təmin edilmişdir

