






Süni intellekt tədqiqatı böyük dil modellərində dramatik əsaslandırmanın pozulmasını aşkar edir
Hətta ən yaxşı AI böyük dil modelləri (LLM) sadə məntiqi suallara gəldikdə dramatik şəkildə uğursuz olur. Bu, Jülich Superkompüter Mərkəzinin (SC), Bristol Universitetinin Elektrik və Elektron Mühəndisliyi Məktəbinin və LAION AI laboratoriyasının tədqiqatçılarının gəldiyi nəticədir.
arXiv preprint serverinə göndərdikləri “Alisa möcüzələr ölkəsində: Ən müasir geniş dil modellərində tam düşünmə bölgüsünü göstərən sadə tapşırıqlar” başlıqlı məqalələrində elm adamları “funksiyaların və düşünmə imkanlarının dramatik şəkildə pozulmasını” təsdiqləyirlər. sınaqdan keçmiş ən müasir LLM-lər və dil modellərinin əsas mülahizələri yerinə yetirmək üçün gizli qabiliyyətə malik olmasına baxmayaraq, onlara möhkəm və ardıcıl şəkildə daxil ola bilməyəcəyini təklif edir.
Tədqiqatın müəllifləri – Marianna Nezhurina, Lucia Cipolina-Kun, Mehdi Cherti və Jenia Jitsev – “elmi və texnoloji ictimaiyyəti indiki nəsil LLM-lərin iddia edilən imkanlarının təcili yenidən qiymətləndirilməsini stimullaşdırmağa” çağırır. Onlar həmçinin əsas mülahizə imkanları ilə bağlı dil modellərində zəif cəhətləri aşkar etmək üçün standartlaşdırılmış meyarların hazırlanmasını tələb edirlər, çünki hazırkı testlər bu ciddi uğursuzluğu aşkar edə bilməyib.
Düzgün əsaslandırmanın əsas nöqtəsi
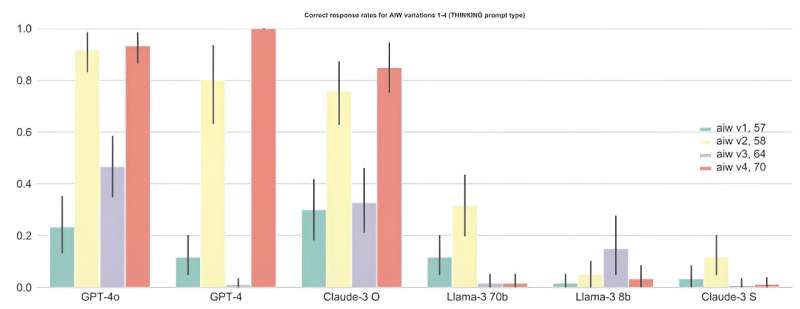
Qəzetdə “AIW problemi” adlandırılan “sağlam düşüncə işi” əslində sadədir: “Alisin N qardaşı və M bacısı var. Alisin qardaşının neçə bacısı var?” N və M (təbii ədədlər həmişə) və qardaş və bacıların sırası müxtəlifdir. Beləliklə, tədqiqatçılar sistematik AIW problem varyasyonları altında müxtəlif modellərin necə davrandığına dair dəqiq icmal əldə etmək üçün müxtəlif nömrələr və operativ növ birləşmələrindən istifadə etdilər.
https://googleads.g.doubleclick.net/pagead/ads?gdpr=0&us_privacy=1—&gpp_sid=-1&client=ca-pub-0536483524803400&output=html&h=135&slotname=2793866484&adk=675901022&adf=1873531024&pi=t.ma~as.2793866484&w=540&abgtt=6&fwrn=4&lmt=1721855593&rafmt=11&format=540×135&url=https%3A%2F%2Ftechxplore.com%2Fnews%2F2024-07-ai-reveals-breakdown-large-language.html&wgl=1&uach=WyJXaW5kb3dzIiwiMTAuMC4wIiwieDg2IiwiIiwiMTI2LjAuNjQ3OC4xODMiLG51bGwsMCxudWxsLCI2NCIsW1siTm90L0EpQnJhbmQiLCI4LjAuMC4wIl0sWyJDaHJvbWl1bSIsIjEyNi4wLjY0NzguMTgzIl0sWyJHb29nbGUgQ2hyb21lIiwiMTI2LjAuNjQ3OC4xODMiXV0sMF0.&dt=1721854455105&bpp=2&bdt=1439&idt=593&shv=r20240722&mjsv=m202407180101&ptt=9&saldr=aa&abxe=1&cookie=ID%3D9ead181ef67abbaa%3AT%3D1721801884%3ART%3D1721855451%3AS%3DALNI_MYoq0akGsLUXhAUIhnaG6TQeS4STg&eo_id_str=ID%3Db268401c0e4aeef7%3AT%3D1721801884%3ART%3D1721855451%3AS%3DAA-AfjYSUg2K_FFfwOkLTloH9McJ&prev_fmts=0x0%2C1423x739&nras=2&correlator=8439921816707&frm=20&pv=1&ga_vid=1057348607.1721801883&ga_sid=1721854455&ga_hid=703940312&ga_fc=1&rplot=4&u_tz=240&u_his=1&u_h=900&u_w=1440&u_ah=860&u_aw=1440&u_cd=24&u_sd=1&dmc=8&adx=347&ady=1622&biw=1423&bih=739&scr_x=0&scr_y=0&eid=44759876%2C44759927%2C44759837%2C44795921%2C95334526%2C95334830%2C95337026%2C95337868%2C95338227%2C95338253%2C31084185%2C31078663%2C31078665%2C31078668%2C31078670&oid=2&pvsid=984134692528446&tmod=153846045&uas=0&nvt=3&ref=https%3A%2F%2Fphys.org%2F&fc=1920&brdim=0%2C0%2C0%2C0%2C1440%2C0%2C1440%2C860%2C1440%2C739&vis=1&rsz=%7C%7CpeEbr%7C&abl=CS&pfx=0&fu=128&bc=31&bz=1&td=1&tdf=0&psd=W251bGwsbnVsbCwibGFiZWxfb25seV80IiwxXQ..&nt=1&ifi=2&uci=a!2&btvi=1&fsb=1&dtd=M
Dəyişikliklərdən asılı olmayaraq, problemin strukturu dəyişməz qalır və düzgün cavab həmişə Alice və onun bacılarının əlavə edilməsi nəticəsində əldə edilir (M + 1). İbtidai sinif uşaqlarının çoxunun artıq əməl edə biləcəyi məntiq . Digər tərəfdən, dil modelləri AIW problemini yalnız təsadüfi olaraq həll edə bildi. Sualın ən sadə versiyası ilə qarşılaşan bir LLM nümunəsi:
“Alisin dörd qardaşı və bir bacısı var. Alisin qardaşının neçə bacısı var?”—”Klassik yanal düşüncə tapmacası – Gəlin daha yaxından nəzər salaq: Alisin dörd qardaşı var. Alisin də bir bacısı (özü də) var. Beləliklə, Alisin hər birinin Qardaşların… (baraban) …bir bacısı var və bu, Alisin özüdür.
Bu inandırıcı görünə bilər, amma yenə də yanlışdır (əlbəttə ki, Alisin qardaşlarının iki bacısı var). Digər sınaqdan keçmiş dil AI-ləri də problemə düşür – sualdan asılı olaraq böyük problem. Bəzən absurd mülahizələrə qarışır, dönə-dönə yanlış nəticələrə gəlir və onları “düzgün” elan edirlər.
Buna görə də problemli olan təkcə yanlış nəticələr deyil, həm də süni intellektlərin onları dəstəkləmək üçün psevdosensual arqumentlərdən istifadə etməsi faktıdır. Hətta tədqiqatçıların onları öz cavablarını tənqidi şəkildə nəzərdən keçirməyə təşviq etmək üçün müdaxilələri də kömək etmir.
Müvafiq olaraq, tədqiqatçılar belə qiymətləndirirlər: “Modellər həmçinin öz səhv həll yollarına güclü həddən artıq inam ifadə edir, eyni zamanda tez-tez cəfəng “mülahizə” kimi izahatlar verirlər … açıq-aşkar uğursuz cavablarının etibarlılığını əsaslandırmaq və dəstəkləmək, onları inandırıcı edir.”
Hər ikinci cavabdan çox səhvdir
Ümumilikdə, LLM-lərin orta düzgün cavab nisbəti 50%-dən xeyli aşağı idi, daha böyük modellər ümumiyyətlə kiçik modellərdən əhəmiyyətli dərəcədə yaxşı performans göstərdi (məsələn, GPT-4o düzgün cavab dərəcəsini 60%-dən bir qədər yuxarı göstərir ki, bu da yenə də aşağıdakı üstünlükləri dəstəkləyir. daha böyük miqyaslı-həmçinin ən böyük miqyaslı modellər güclü əsas mülahizələrə malik model üçün kifayət qədər yaxşı performans göstərmir.
Xüsusilə, hətta kiçik AIW problem varyasyonları arasında müşahidə edilən çox güclü dalğalanmalar modellərin əsaslı əsas mülahizələrə qadir olmadığının aydın göstəricisidir və beləliklə, düzgün həllin təmin edilməsində əhəmiyyət kəsb etməyən kiçik problem dəyişiklikləri ilə üzləşdikdə belə çaşqınlıq yaranır.
Sualın daha çətin versiyası (“AIW+ problemi”) nəticədə bütün modelləri düşünmə qabiliyyətlərinin kənarına itələdi. Tədqiqatçıların fikrincə, sınaqdan keçirilmiş modellərin çoxu çox sadə AIW problemində uğursuzluqla yanaşı, mülahizə də daxil olmaqla müxtəlif imkanları yoxlamaq üçün nəzərdə tutulmuş müxtəlif standartlaşdırılmış meyarlarda çox yüksək ballar əldə edir.
Buna görə də alimlər öz məqalələrində bu meyarların bu modellərin əsas mülahizələrindəki çatışmazlıqları düzgün əks etdirmədiyini, həmçinin model müqayisəsi üçün mövcud standartlaşdırılmış etalonların istifadəsini şübhə altına aldığını təklif edirlər.
https://googleads.g.doubleclick.net/pagead/ads?gdpr=0&us_privacy=1—&gpp_sid=-1&client=ca-pub-0536483524803400&output=html&h=135&slotname=2793866484&adk=675901022&adf=1897700409&pi=t.ma~as.2793866484&w=540&abgtt=6&fwrn=4&lmt=1721855657&rafmt=11&format=540×135&url=https%3A%2F%2Ftechxplore.com%2Fnews%2F2024-07-ai-reveals-breakdown-large-language.html&wgl=1&uach=WyJXaW5kb3dzIiwiMTAuMC4wIiwieDg2IiwiIiwiMTI2LjAuNjQ3OC4xODMiLG51bGwsMCxudWxsLCI2NCIsW1siTm90L0EpQnJhbmQiLCI4LjAuMC4wIl0sWyJDaHJvbWl1bSIsIjEyNi4wLjY0NzguMTgzIl0sWyJHb29nbGUgQ2hyb21lIiwiMTI2LjAuNjQ3OC4xODMiXV0sMF0.&dt=1721854455107&bpp=5&bdt=1440&idt=624&shv=r20240722&mjsv=m202407180101&ptt=9&saldr=aa&abxe=1&cookie=ID%3D9ead181ef67abbaa%3AT%3D1721801884%3ART%3D1721855451%3AS%3DALNI_MYoq0akGsLUXhAUIhnaG6TQeS4STg&eo_id_str=ID%3Db268401c0e4aeef7%3AT%3D1721801884%3ART%3D1721855451%3AS%3DAA-AfjYSUg2K_FFfwOkLTloH9McJ&prev_fmts=0x0%2C1423x739%2C540x135%2C1005x124&nras=3&correlator=8439921816707&frm=20&pv=1&ga_vid=1057348607.1721801883&ga_sid=1721854455&ga_hid=703940312&ga_fc=1&rplot=4&u_tz=240&u_his=1&u_h=900&u_w=1440&u_ah=860&u_aw=1440&u_cd=24&u_sd=1&dmc=8&adx=347&ady=3234&biw=1423&bih=739&scr_x=0&scr_y=282&eid=44759876%2C44759927%2C44759837%2C44795921%2C95334526%2C95334830%2C95337026%2C95337868%2C95338227%2C95338253%2C31084185%2C31078663%2C31078665%2C31078668%2C31078670&oid=2&psts=AOrYGsmiK0dWBdPKt8BVfj3tfQytfZ9zWDm2GXDoyo947llHMIeBYrnUQPIjOjPoE2edO4Zj4LfrjBN6R6Gu6Zc1WO8Eh7fN3c5SPTAtUWRatwyt9ppZ-Q%2CAOrYGsnRqy7qErqbLF9coHbtpGREpRVBuneNRiGPDJiJv1PxemgO-Pf9-YuEdikUv7pMjeIqvjD7Wqxgh7SAtz3K3JhMxOdW&pvsid=984134692528446&tmod=153846045&uas=3&nvt=3&ref=https%3A%2F%2Fphys.org%2F&fc=1920&brdim=0%2C0%2C0%2C0%2C1440%2C0%2C1440%2C860%2C1440%2C739&vis=1&rsz=%7C%7CpeEbr%7C&abl=CS&pfx=0&fu=128&bc=31&bz=1&td=1&tdf=0&psd=W251bGwsbnVsbCwibGFiZWxfb25seV80IiwxXQ..&nt=1&ifi=3&uci=a!3&btvi=3&fsb=1&dtd=M
Test skamyasında dil modelləri
Kağız hələ ekspertlər tərəfindən nəzərdən keçirilməsə də, onun tapıntıları artıq dalğalar yaradır. LLM-lər həqiqətən nə dərəcədə bacarıqlıdır? İbtidai məktəb səviyyəli tapşırıqları yerinə yetirmədikdə LLM-lərin istifadəsi nə deməkdir? Həmmüəllif Jitsev (JSC) deyir: “Məqaləmiz nəticəsində müzakirələr və sorğular bizi sıxışdırıb.” Alimlərin tapıntıları bir çox şeyi sual altına qoyur və dil modellərinin səriştəsi ilə bağlı əlavə araşdırmalar aparır.
Jitsev deyir: “Məqaləmiz düzgün əsas mülahizələrə əməl etməklə düzgün nəticələr çıxarmaq üçün dil modellərinin faktiki qabiliyyətləri haqqında son dərəcə vacib yeni anlayışlar təqdim edir – cari modellərdə əsas mülahizələrin necə və niyə pozulduğunu anlamaq üçün burada əlavə tədqiqatlara ehtiyac var. belə asan problemlər.”
Ətraflı məlumat: Marianna Nezhurina və digərləri, Alisa Möcüzələr Diyarında: Ən Müasir Böyük Dil Modellərində Tam Mülahizə Ayrılmalarını Göstərən Sadə Tapşırıqlar, arXiv (2024). DOI: 10.48550/arxiv.2406.02061
Jurnal məlumatı: arXiv

