





Tədqiqatçı 24 saatlıq AI səs köməkçisi üçün imkanlar açan “SpeechSSM” hazırlayır
Bu yaxınlarda danışıq dili modelləri (SLMs) linqvistik və qeyri-linqvistik məlumatları anlamaq və yaratmaq üçün mətn olmadan insan nitqini öyrənməklə mətn əsaslı dil modellərinin məhdudiyyətlərini aşan yeni nəsil texnologiya kimi vurğulanır.
Bununla belə, mövcud modellər podkastlar, audiokitablar və səs köməkçiləri üçün tələb olunan uzunmüddətli məzmunun yaradılmasında əhəmiyyətli məhdudiyyətlər göstərir.
Ph.D. Koreya Qabaqcıl Elm və Texnologiya İnstitutunun (KAIST) Elektrik Mühəndisliyi Məktəbində professor Yonq Man Ronun tədqiqat qrupundan namizəd, Sejin Park, vaxt məhdudiyyəti olmadan ardıcıl və təbii nitq yaratmağa imkan verən “SpeechSSM” inkişaf etdirərək bu məhdudiyyətləri aradan qaldırmağa müvəffəq oldu .
Əsər arXiv preprint serverində dərc edilib və ICML (Maşın Öyrənməsi üzrə Beynəlxalq Konfrans) 2025- də təqdim olunacaq .
SLM-lərin əsas üstünlüyü onların insan danışanlarının unikal akustik xüsusiyyətlərindən istifadə etməklə, hətta iri miqyaslı modellərdə belə yüksək keyfiyyətli nitqin sürətli generasiyasına imkan verən aralıq mətnə çevrilmədən nitqi birbaşa emal etmək qabiliyyətidir.
Bununla belə, mövcud modellər nitqi incə fraqmentlərə bölmək yolu ilə çox təfərrüatlı məlumatların tutulması zamanı artan “nitq işarəsi həlli” və yaddaş sərfiyyatı səbəbindən uzunmüddətli nitq üçün semantik və natiq ardıcıllığını saxlamaqda çətinliklərlə üzləşirdi.
SpeechSSM növbə ilə son məlumatlara fokuslanan “diqqət qatlarını” və ümumi hekayə axınını (uzunmüddətli kontekst) yadda saxlayan “təkrarlanan təbəqələri” yerləşdirən “hibrid strukturdan” istifadə edir. Bu, uzun müddət nitq yaratdıqda belə, hekayənin ahəngdarlığını itirmədən rəvan axmasına imkan verir.
https://googleads.g.doubleclick.net/pagead/ads?gdpr=0&us_privacy=1—&gpp_sid=-1&client=ca-pub-0536483524803400&output=html&h=280&slotname=2793866484&adk=2520359048&adf=1100001614&pi=t.ma~as.2793866484&w=750&abgtt=6&fwrn=4&fwrnh=0&lmt=1751867767&rafmt=1&armr=3&format=750×280&url=https%3A%2F%2Ftechxplore.com%2Fnews%2F2025-07-speechssm-possibilities-hour-ai-voice.html&fwr=0&rpe=1&resp_fmts=3&wgl=1&uach=WyJXaW5kb3dzIiwiMTkuMC4wIiwieDg2IiwiIiwiMTM4LjAuNzIwNC45NyIsbnVsbCwwLG51bGwsIjY0IixbWyJOb3QpQTtCcmFuZCIsIjguMC4wLjAiXSxbIkNocm9taXVtIiwiMTM4LjAuNzIwNC45NyJdLFsiR29vZ2xlIENocm9tZSIsIjEzOC4wLjcyMDQuOTciXV0sMF0.&dt=1751867766960&bpp=16&bdt=170&idt=76&shv=r20250630&mjsv=m202507010101&ptt=9&saldr=aa&abxe=1&cookie=ID%3Dfdc40d724f2dca57%3AT%3D1735367325%3ART%3D1751867322%3AS%3DALNI_MYStQ6fUQQQLyo5Z7z1h-XhXcWBtA&gpic=UID%3D00000f80eacffadc%3AT%3D1735367325%3ART%3D1751867322%3AS%3DALNI_MYaOugky0UawScoidzfbXof3-N-iw&eo_id_str=ID%3D878d521b85743f4c%3AT%3D1751526237%3ART%3D1751867322%3AS%3DAA-AfjZCLruwaFzoQORvGPwXS3Y2&prev_fmts=0x0%2C1200x280&nras=1&correlator=8031544425406&frm=20&pv=1&rplot=4&u_tz=240&u_his=1&u_h=1080&u_w=1920&u_ah=1032&u_aw=1920&u_cd=24&u_sd=1&dmc=8&adx=448&ady=1916&biw=1905&bih=945&scr_x=0&scr_y=0&eid=31093232%2C95353387%2C95362656%2C95365226%2C95365234%2C95365112%2C95359266%2C95365119%2C95365797%2C95360684%2C95340253%2C95340255&oid=2&pvsid=828346909136434&tmod=1918084381&uas=0&nvt=1&ref=https%3A%2F%2Fphys.org%2F&fc=1920&brdim=0%2C0%2C0%2C0%2C1920%2C0%2C1920%2C1032%2C1920%2C945&vis=1&rsz=%7C%7CpeEbr%7C&abl=CS&pfx=0&fu=128&bc=31&bz=1&td=1&tdf=2&psd=W251bGwsbnVsbCxudWxsLDNd&nt=1&ifi=2&uci=a!2&btvi=2&fsb=1&dtd=388
Bundan əlavə, yaddaş istifadəsi və hesablama yükü giriş uzunluğu ilə kəskin artmır, sabit və səmərəli öyrənməyə və uzunmüddətli nitqin yaranmasına imkan verir.
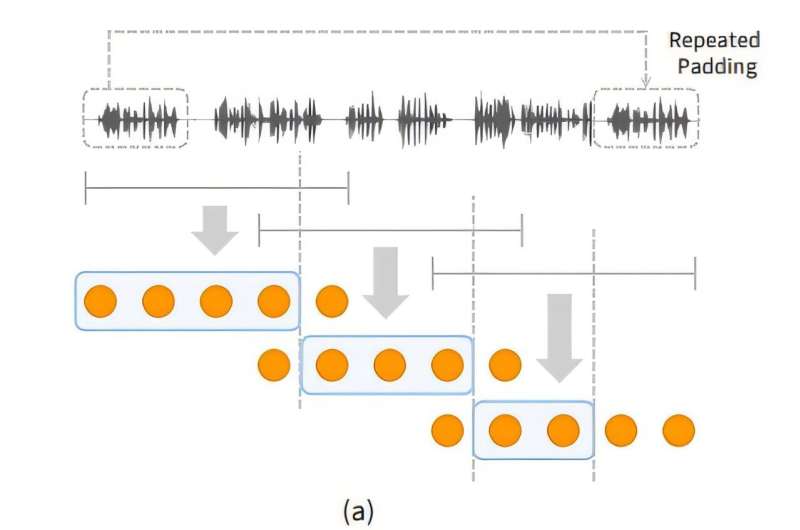
SpeechSSM nitq məlumatlarını qısa, sabit vahidlərə (pəncərələrə) bölmək, hər bir vahidi müstəqil şəkildə emal etmək və sonra uzun nitq yaratmaq üçün onları birləşdirməklə qeyri-məhdud nitq ardıcıllığını effektiv şəkildə emal edir.
Bundan əlavə, nitq yaratma mərhələsində o, bir anda bir simvol və ya bir söz yaratmaq əvəzinə, eyni anda birdən çox hissəni sürətlə yaradan, yüksək keyfiyyətli nitqin sürətli generasiyasına imkan verən “Avtoreqressiv olmayan” audio sintez modelindən (SoundStorm) istifadə edir.
Mövcud modellər adətən təxminən 10 saniyəlik qısa nitq modellərini qiymətləndirsə də, Se Jin Park 16 dəqiqəyə qədər nitq yaratmağa qadir olan “LibriSpeech-Long” öz-özünə qurulmuş etalon verilənlər bazası əsasında nitq yaratmaq üçün yeni qiymətləndirmə tapşırıqları yaratdı.
Yalnız qrammatik düzgünlüyünü göstərən mövcud nitq modelinin qiymətləndirmə metikası olan PPL (Perplexity) ilə müqayisədə o, zamanla məzmun uyğunluğunu qiymətləndirmək üçün “SC-L (zamanla semantik uyğunluq)” və zamanla daha çox effektivliyi və təbiiliyi qiymətləndirmək üçün “N-MOS-T (zamanla təbiilik orta rəy hesabı)” kimi yeni qiymətləndirmə ölçülərini təklif etdi.
Bu yeni qiymətləndirmələr vasitəsilə təsdiq olundu ki, SpeechSSM danışıq dili modeli tərəfindən yaradılan nitq ardıcıl olaraq ilkin göstərişdə qeyd olunan konkret şəxsləri əks etdirir və yeni personajlar və hadisələr uzun müddətli nəsillərə baxmayaraq, təbii və kontekstdə ardıcıl şəkildə inkişaf edir.
Bu, öz mövzusunu asanlıqla itirməyə və uzun müddətli generasiya zamanı təkrar nümayiş etdirməyə meylli olan mövcud modellərlə kəskin şəkildə ziddiyyət təşkil edir.
Sejin Park izah etdi: “Mövcud danışıq dili modellərinin uzun müddətli nəsildə məhdudiyyətləri var idi , buna görə də bizim məqsədimiz faktiki insan istifadəsi üçün uzunmüddətli nitq yarada bilən danışıq dili modelini inkişaf etdirmək idi.”
O, əlavə etdi: “Bu tədqiqat nailiyyətinin uzun kontekstlərdə ardıcıl məzmunu saxlamaqla və mövcud metodlardan daha səmərəli və tez real vaxtda cavab verməklə səsli köməkçilər kimi müxtəlif növ səs məzmunu yaradılmasına və səsli AI sahələrinə böyük töhfə verəcəyi gözlənilir.”
Se Jin Parkın ilk müəllifi olduğu bu araşdırma Google DeepMind ilə əməkdaşlıqda aparılıb.
Daha çox məlumat: Se Jin Park və digərləri, Danışıq Dil Modelləri ilə Uzun Forma Nitq Nəsil, arXiv (2024). DOI: 10.48550/arxiv.2412.18603
Müşaiyət olunan demo: SpeechSSM Nəşrləri .
Jurnal məlumatı: arXiv Koreya Qabaqcıl Elm və Texnologiya İnstitutu (KAIST) tərəfindən təmin edilmişdir