







Tədqiqatlar göstərir ki, mükafatların vaxtı öyrənmədə əsas rol oynayır
İnqrid Fadelli , Medical Xpress tərəfindən
Stephanie Baum tərəfindən redaktə edilib , Robert Egan tərəfindən nəzərdən keçirilib
Tercih edilən mənbə kimi əlavə edin
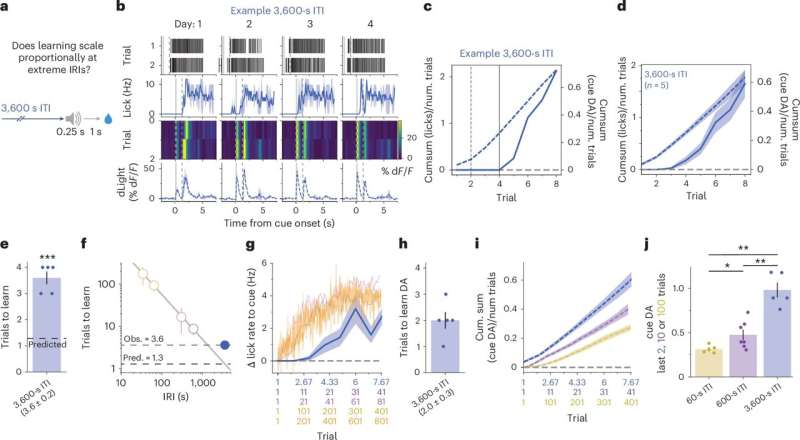
Öyrənmə sürəti həddindən artıq sınaq aralığı ilə artır, lakin mütənasib deyil. Mənbə: Nature Neuroscience (2026). DOI: 10.1038/s41593-026-02206-2
Təxminən bir əsrdir ki, psixologiya və nevrologiya tədqiqatçıları insanların və digər heyvanların yeni bacarıqlar qazandıqları və ya müəyyən vəziyyətlərlə mübarizə aparmağı öyrəndikləri prosesləri anlamağa çalışırlar. Tanınmış və geniş sənədləşdirilmiş öyrənmə növlərindən biri müəyyən hadisələrdən sonra mükafat və ya cəza ilə müşayiət olunduqda baş verir.
Bu ssenarilərdə beyin müəyyən siqnalları və ya işarələri yaxşı və ya pis nəticə ilə əlaqələndirməyi öyrənir. Keçmiş tapıntılar göstərir ki, neyrotransmitter dopamin müsbət təcrübənin gözləntisini göstərən və mükafatların ardınca getmək üçün motivasiyanı artıran bir tədris siqnalı təmin etməklə bu prosesdə mərkəzi rol oynayır.
Bu günə qədər təqdim edilən psixoloji nəzəriyyələrin əksəriyyəti mükafata əsaslanan öyrənmənin tədricən baş verən bir proses olduğunu və hər dəfə müəyyən bir hərəkətdən və ya stimuldan sonra mükafat yaşadıqda beyin gələcək mükafatlarla bağlı gözləntilərini bir qədər “düzəldir” olduğunu göstərir. İndiyə qədər bu prosesin bir mükafatla digəri arasında keçən vaxtdan asılı olmayaraq baş verdiyinə inanılırdı.
Kaliforniya Universiteti-San-Fransisko və Kaliforniya Universiteti-Berkli tədqiqatçıları bu yaxınlarda siçan üzərində aparılan bir araşdırmada bu fərziyyəni şübhə altına aldılar və mükafat əsaslı öyrənmənin gücünün eyni stimuldan sonra siçanın neçə dəfə mükafatlandırılmasından deyil, həm də mükafatlar arasındakı vaxtdan asılı olduğunu irəli sürdülər. Onların ” Nature Neuroscience” jurnalında dərc olunmuş məqaləsi mövcud öyrənmə, qərar qəbuletmə və hətta potensial olaraq asılılıq modellərini yenidən formalaşdıra bilər.
“Beyin bir işarənin mükafat proqnozlaşdırdığını necə öyrənir?” deyə məqalənin baş müəllifi Vijay Mohan K. Namboodiri Medical Xpress-ə danışarkən bildirib. “Biz əvvəllər heyvanların proqnozları birbaşa öyrənmək əvəzinə, işarələrin sistematik olaraq mükafatlardan əvvəl olub -olmadığını öyrəndiklərini irəli sürən bir məqalə dərc etmişdik . Qısaca desək, fikrimiz ondan ibarət idi ki, mümkün işarələrin gələcək təsirlərini öyrənmək əvəzinə, heyvanlar mənalı təsirlərin səbəblərini müəyyən etmək üçün yaddaşlarına baxsınlar, yəni təsirlərdən zamanla geri baxaraq səbəb-nəticə əlaqələrini öyrənsinlər.”
Əvvəlki məqaləni dərc etdikdən qısa müddət sonra Nambudiri və həmkarları başa düşdülər ki, onların tapıntıları, eksperimental sınaqlar zamanla ara verildikdə heyvanların işarələr və mükafatlar arasındakı əlaqələri daha tez öyrəndiyini də göstərə bilər. Bu, heyvanların nə qədər işarə-mükafat cütləşməsindən asılı olmayaraq, müəyyən bir müddət ərzində mükafatlardan öyrənmələrini nəzərdə tutur.
Nambudiri bildirib ki, “Bu proqnozu sınaqdan keçirmək üçün ilk cəhdimizdə Dr. Burke bir neçə heyvanı işarə-mükafat cütləşmələri arasında 10 dəqiqəlik fərqlə sınaqdan keçirib. Bu heyvanlar işarə-mükafat cütləşmələri arasında bir dəqiqəlik fərqdən istifadə etdiyimiz adi heyvanlarımızdan daha sürətli öyrəniblər. Bu erkən nəticə bizə orada maraqlı bir şeyin olduğunu göstərdi. Bundan sonra öyrənmə sürətinin idarə olunmasını tənzimləyən bir qaydanın olub-olmadığını və öyrənmə sürətinin işarə-mükafat təcrübələri arasındakı vaxtla mütənasib şəkildə miqyaslanıb-miqyaslanmadığını sınaqdan keçirməyə başladıq.”
Mükafat əsaslı öyrənmədə vaxtlamanın təsirini araşdırmaq
Komandanın son tədqiqatının əsas məqsədi mükafat əsaslı öyrənmənin heyvanların yaşadığı işarə-mükafat cütləşmələrinin sayından deyil, bir mükafatla digəri arasındakı vaxtdan asılı olması ehtimalını araşdırmaq idi. Bunu etmək üçün onlar yetkin siçanları əhatə edən bir sıra təcrübələr apardılar.
Siçanlar sadə Pavlov kondisioner tapşırıqları üzrə təlim keçiblər. Bunlar heyvanın qısa bir səs eşidib sonra mükafat (yəni bir az şəkərli su) aldığı tapşırıqlardır. Nambudiri və həmkarları təcrübələrində heyvanların yaşadığı işarə-mükafat cütləşmələrinin sayını və zamanla nə qədər uzaq olduqlarını diqqətlə manipulyasiya ediblər.
Nambudiri izah etdi: “Eyni ümumi təlim müddəti ərzində (məsələn, bir saat), çoxlu sayda yaxın məsafəli replika-mükafat cütləşmələri (məsələn, 120) yaşayan heyvanları çox az, geniş məsafəli cütləşmələr (məsələn, altı) yaşayan heyvanlarla müqayisə etdik. Davranış baxımından, öyrənməni replikaya şərti reaksiyaları ölçməklə, xüsusən də heyvanların qarşıdan gələn şəkər məhlulunu gözləyərək boruda nə qədər tez yalamağa başladığını ölçməklə ölçdük.”
Ənənəvi psixoloji modellər göstərir ki, eyni vaxt çərçivəsində daha çox işarə-mükafat cütləşməsi daha güclü öyrənməyə səbəb olacaq və bu da siçanların tanış səsi eşidən kimi şəkərli suyu axtarmasını nəzərdə tutur. Lakin təəccüblüdür ki, tədqiqatçılar müəyyən bir müddətdən sonra bütün siçanların bir neçə və ya daha çox cütləşmə yaşamasından asılı olmayaraq, əlaqəni yaxşı öyrəndiklərini aşkar etdilər.
Nambudiri bildirib ki, “Tədqiqatçılar cütləşmələrin zamanla yayılması hər cütləşmə üçün öyrənməni sürətləndirdiyini bilirdilər, lakin yenə də öyrənmənin son səviyyəsinin cütləşmələrin ümumi sayından asılı olduğu güman edilirdi. Təcrübələrimiz göstərdi ki, bunun əvəzinə ümumi öyrənmə sayla deyil, zamanla müəyyən edilir.”
Tədqiqatçılar hipotezlərini daha da sınaqdan keçirmək üçün bir sıra əlavə testlər apardılar və bu testlərdə işarələr, mükafatlar və işarə-mükafat cütləşmələri arasındakı intervalları manipulyasiya etdilər.
Nambudiri bildirib ki, “Bu, öyrənmənin bu zaman parametrlərinin funksiyası kimi necə dəyişdiyini ölçməyə imkan verdi. Bu təcrübələrdə nəticələr ardıcıl olaraq sadə riyazi qayda ilə izah edildi. Hər bir işarə-mükafat təcrübəsindən öyrənmə miqdarı mükafatlar arasındakı orta vaxtla mütənasibdir.”
Nambudiri və həmkarları nəhayət aşkar etdikləri zamandan asılı öyrənmə mexanizminin bioloji və neyroelmi əsaslarına işıq salmağa çalışdılar. Bunu etmək üçün onlar mükafat öyrənmə və zövq axtarma davranışı ilə əlaqəli beyin bölgəsindəki dopamin siqnallarını ölçdülər. Bu, nüvə akumbensi adlanır.
Komanda genetik kodlanmış flüoresan dopamin sensorlarından istifadə edərək bu dopamin siqnallarını izlədi . Siçanlar işarələrə məruz qaldıqda və tədricən bu işarələri mükafatlarla əlaqələndirməyi öyrəndikdə onları izlədilər.
Nambudiri bildirib ki, “Biz dopamin siqnallarının eyni öyrənmə qaydasına əməl etdiyini aşkar etdik: Dopamin siqnal reaksiyalarındakı dəyişiklik sürəti, siqnal-mükafat cütləşmələrinin sayından deyil, mükafatlar arasındakı orta vaxtdan asılı idi. Davranış və dopamin aktivliyi arasındakı bu paralel, beynin mükafat sisteminin zamana əsaslanan öyrənmə qaydasını tətbiq etdiyini və heyvanların mükafatlardan necə öyrəndiyini göstərən sadə bir bioloji əsası ortaya qoyduğunu göstərir.”
Ənənəvi öyrənmə modellərinin yenidən nəzərdən keçirilməsi
Nambudiri və həmkarları tərəfindən toplanan son tapıntılar nevrologiya və psixologiya tədqiqatları üçün mühüm nəticələrə səbəb ola bilər. Əgər sonrakı təcrübələrdə təsdiqlənərsə, onlar mükafat əsaslı öyrənmənin mövcud anlayışını yenidən müəyyənləşdirə və yeni nəzəri modellərin yaradılmasına kömək edə bilər.
Gələcəkdə bu tədqiqat, potensial olaraq, bir neçə təcrübədən öyrənmək üçün mükafatlar arasındakı vaxtı nəzərə alan süni intellekt (Sİ) agentlərinin yetişdirilməsi üçün yeni yanaşmaların yaradılmasına da ilham verə bilər. Nəhayət, bu, asılılıq və maddə istifadəsi pozğunluqlarının (SUD) bəzi əsaslarını, eləcə də faydasız mükafat axtarma davranışları ilə əlaqəli digər ruhi sağlamlıq pozğunluqlarını daha çox işıqlandırmağa kömək edə bilər.
Nambudiri əlavə edib ki, “Bizim işimiz dopamin vasitəçiliyi ilə öyrənmə ilə əlaqəli xəstəlikləri, məsələn, asılılığı daha yaxşı başa düşməyə kömək edə bilər və həm insanlar, həm də süni intellekt sistemləri üçün öyrənməni optimallaşdırmaq üçün vacib qaydalar təqdim edə bilər. Hazırkı tədqiqatlarımız beyində bu öyrənmə sürətinin idarə olunmasını təmin etmək üçün hesablanmış mükafatlar arasındakı müddətin harada olduğunu və bu qaydanın dərman mükafatlarına və ya digər öyrənmə formalarına şamil edilib-edilmədiyini anlamağa yönəlib.”
Müəllifimiz İnqrid Fadelli tərəfindən sizin üçün yazılmış, Stefani Baum tərəfindən redaktə edilmiş və Robert Egan tərəfindən faktlar yoxlanılmış və nəzərdən keçirilmiş bu məqalə diqqətli insan əməyinin nəticəsidir. Müstəqil elmi jurnalistikanı yaşatmaq üçün sizin kimi oxuculara güvənirik. Bu reportaj sizin üçün vacibdirsə, xahiş edirik ianə etməyi düşünün (xüsusilə aylıq). Təşəkkür olaraq reklamsız hesab əldə edəcəksiniz .
Nəşr detalları
Mükafatlar arasındakı müddət davranış və dopaminergik öyrənmə sürətini idarə edir. Nature Neuroscience (2026). DOI: 10.1038/s41593-026-02206-2
Jurnal məlumatları: Təbiət Neyrologiyası
Əsas tibbi anlayışlar
DopaminKondisioner, KlassikNüvə AkumbensləriMaddə ilə əlaqəli pozğunluqlar
Klinik kateqoriyalar
NevrologiyaPsixologiya və Ruhi sağlamlıq
© 2026 Science X Network

