




‘Termometr’ texnikası süni intellekt modelinin yanlış cavablara həddindən artıq arxayın olmasının qarşısını alır
İnsanlar məqalənin tərcüməsindən tutmuş maliyyə fırıldaqlarının müəyyən edilməsinə qədər böyük bir sıra tapşırıqlar üçün böyük dil modellərindən istifadə edirlər. Bununla belə, bu modellərin inanılmaz imkanlarına və çox yönlülüyünə baxmayaraq, onlar bəzən qeyri-dəqiq cavablar yaradırlar.
Bundan əlavə, modellər səhv cavablara həddən artıq arxayın ola və ya düzgün cavablara inamsız ola bilər ki, bu da istifadəçinin modelə nə vaxt etibar edilə biləcəyini bilməsini çətinləşdirir.
Tədqiqatçılar adətən maşın öyrənmə modelinin etibarlılıq səviyyəsinin dəqiqliyinə uyğun olmasını təmin etmək üçün kalibrləyirlər. Yaxşı kalibrlənmiş bir model səhv proqnoza daha az inamlı olmalıdır və əksinə. Lakin böyük dil modelləri (LLM) müxtəlif tapşırıqların sonsuz görünən kolleksiyasına tətbiq oluna bildiyi üçün ənənəvi kalibrləmə üsulları səmərəsizdir.
İndi MIT və MIT-IBM Watson AI Lab-dan olan tədqiqatçılar böyük dil modellərinə uyğunlaşdırılmış kalibrləmə metodunu təqdim etdilər. Onların Termometr adlanan metodu onu kalibrləmək üçün böyük bir dil modelinin üstündə işləyən daha kiçik, köməkçi modelin qurulmasını nəzərdə tutur.
Termometr digər yanaşmalardan daha səmərəlidir – daha az enerji tələb edən hesablama tələb edir – eyni zamanda modelin dəqiqliyini qoruyur və daha əvvəl görmədiyi tapşırıqlar üçün daha yaxşı kalibrlənmiş cavablar yaratmağa imkan verir.
Müxtəlif tapşırıqlar üçün LLM-nin səmərəli kalibrlənməsinə imkan verməklə, Termometr istifadəçilərə modelin yalan proqnozlara həddən artıq arxayın olduğu situasiyaları təyin etməyə kömək edə bilər və nəticədə onların uğursuz ola biləcəyi bir vəziyyətdə həmin modeli tətbiq etmələrinin qarşısını alır.
Maohao Shen deyir: “Termometr ilə biz istifadəçiyə modelin qeyri-müəyyənliyini əks etdirəcək şəkildə modelin cavabının dəqiq və ya qeyri-dəqiq olduğunu bildirmək üçün aydın siqnal vermək istəyirik ki, onlar bu modelin etibarlı olub olmadığını bilsinlər”. elektrik mühəndisliyi və kompüter elmləri (EECS) aspirantı və Termometr haqqında məqalənin aparıcı müəllifidir.
Shen, Elektron Tədqiqat Laboratoriyasında Siqnallar, Məlumatlar və Alqoritmlər Laboratoriyasına rəhbərlik edən və MIT-IBM Watson AI Laboratoriyasının üzvü olan Sumitomo Mühəndislik Professoru Gregory Wornell tərəfindən kağıza qoşuldu; böyük müəllif Soumya Ghosh, MIT-IBM Watson AI Laboratoriyasının tədqiqat işçisi; eləcə də MIT və MIT-IBM Watson AI Lab-da digərləri kimi.
Tədqiqat bu yaxınlarda iyulun 21-dən iyulun 27-dək Avstriyanın paytaxtı Vyanada keçirilən Maşın Öyrənməsi üzrə Beynəlxalq Konfransda ( ICML 2024 ) təqdim olunub. O, arXiv preprint serverində mövcuddur .
https://googleads.g.doubleclick.net/pagead/ads?client=ca-pub-0536483524803400&output=html&h=135&slotname=2793866484&adk=675901022&adf=1873531024&pi=t.ma~as.2793866484&w=540&abgtt=6&fwrn=4&lmt=1722498601&rafmt=11&format=540×135&url=https%3A%2F%2Ftechxplore.com%2Fnews%2F2024-07-thermometer-technique-ai-overconfident-wrong.html&wgl=1&uach=WyJXaW5kb3dzIiwiMTUuMC4wIiwieDg2IiwiIiwiMTI3LjAuNjUzMy43NCIsbnVsbCwwLG51bGwsIjY0IixbWyJOb3QpQTtCcmFuZCIsIjk5LjAuMC4wIl0sWyJHb29nbGUgQ2hyb21lIiwiMTI3LjAuNjUzMy43NCJdLFsiQ2hyb21pdW0iLCIxMjcuMC42NTMzLjc0Il1dLDBd&dt=1722498601254&bpp=1&bdt=216&idt=249&shv=r20240729&mjsv=m202407250101&ptt=9&saldr=aa&abxe=1&cookie=ID%3Db9da3e02405744d8%3AT%3D1721367090%3ART%3D1722498232%3AS%3DALNI_MbCxflFG1tK4Eg0JnLd1ADPoQRHCw&eo_id_str=ID%3D00ebd51b515acd52%3AT%3D1721367090%3ART%3D1722498232%3AS%3DAA-AfjajUyEPj_hS0T6XCNoUbt04&prev_fmts=0x0&nras=1&correlator=4367303089656&frm=20&pv=1&rplot=4&u_tz=240&u_his=1&u_h=864&u_w=1536&u_ah=816&u_aw=1536&u_cd=24&u_sd=1.25&dmc=8&adx=395&ady=2122&biw=1519&bih=695&scr_x=0&scr_y=0&eid=44759875%2C44759926%2C44759842%2C44798934%2C95334525%2C95334829%2C95337026%2C95337868%2C95338228%2C95335247%2C95337094%2C95338262%2C95336267%2C31078663%2C31078665%2C31078668%2C31078670&oid=2&pvsid=2159312491647015&tmod=1517655612&uas=0&nvt=3&ref=https%3A%2F%2Fphys.org%2F&fc=1920&brdim=0%2C0%2C0%2C0%2C1536%2C0%2C1536%2C816%2C1536%2C695&vis=1&rsz=%7C%7CpeEbr%7C&abl=CS&pfx=0&fu=128&bc=31&bz=1&td=1&tdf=0&psd=W251bGwsbnVsbCwibGFiZWxfb25seV8xIiwxXQ..&nt=1&ifi=2&uci=a!2&btvi=1&fsb=1&dtd=265
Universal kalibrləmə
Ənənəvi maşın öyrənmə modelləri adətən bir tapşırığı yerinə yetirmək üçün nəzərdə tutulduğundan, onların kalibrlənməsi adətən bir tapşırıq üçün xüsusi metodu əhatə edir. Digər tərəfdən, LLM-lər bir çox tapşırıqları yerinə yetirmək üçün çevikliyə malik olduğundan, bu modeli bir tapşırıq üçün kalibrləmək üçün ənənəvi metoddan istifadə edərək, onun digər tapşırıqdakı performansına zərər verə bilər.
LLM-nin kalibrlənməsi çox vaxt müxtəlif proqnozlar əldə etmək üçün modeldən bir neçə dəfə nümunə götürməyi və sonra daha yaxşı kalibrlənmiş inamı əldə etmək üçün bu proqnozları birləşdirməyi əhatə edir. Lakin, bu modellərin milyardlarla parametrləri olduğundan, bu cür yanaşmaların hesablama xərcləri sürətlə artır.
“Müəyyən mənada, böyük dil modelləri universaldır, çünki onlar müxtəlif tapşırıqların öhdəsindən gələ bilirlər. Beləliklə, bir çox müxtəlif tapşırıqların öhdəsindən gələ bilən universal kalibrləmə metoduna ehtiyacımız var”, – Şen deyir.
Termometr ilə tədqiqatçılar yeni bir tapşırıq üçün LLM-ni səmərəli şəkildə kalibrləmək üçün temperatur miqyası adlı klassik kalibrləmə metodundan istifadə edən çox yönlü bir texnika hazırladılar.
Bu kontekstdə “temperatur” modelin inamını onun proqnozlaşdırma dəqiqliyinə uyğunlaşdırmaq üçün istifadə edilən miqyaslama parametridir. Ənənəvi olaraq, tapşırıq üçün xüsusi nümunələrin etiketli doğrulama məlumat dəstindən istifadə edərək düzgün temperatur müəyyən edilir.
LLM-lər tez-tez yeni tapşırıqlara tətbiq olunduğundan, etiketli məlumat dəstlərini əldə etmək demək olar ki, qeyri-mümkün ola bilər. Məsələn, yeni məhsul haqqında müştəri suallarını cavablandırmaq üçün LLM tətbiq etmək istəyən istifadəçinin çox güman ki, bu cür sual və cavabları ehtiva edən verilənlər bazası yoxdur.
Tədqiqatçılar etiketli verilənlər toplusundan istifadə etmək əvəzinə, bu yeni tapşırıq üçün onu kalibrləmək üçün lazım olan temperaturu avtomatik olaraq proqnozlaşdırmaq üçün LLM üzərində işləyən köməkçi modeli öyrədirlər.
Onlar Termometr modelini öyrətmək üçün bir neçə təmsilçi tapşırığın etiketli verilənlər toplusundan istifadə edirlər, lakin o, öyrədildikdən sonra əlavə etiketli məlumatlara ehtiyac olmadan oxşar kateqoriyada yeni tapşırıqlara ümumiləşdirilə bilər.
Məsələn, həndəsə və ya biologiya ilə bağlı suallara cavab verəcək LLM-nin kalibrlənməsi üçün, bəlkə də biri cəbr sualları və digəri tibbi suallar daxil olmaqla, çoxseçimli sual verilənlər bazası toplusunda təlim keçmiş Termometr modeli istifadə edilə bilər.
Ghosh deyir: “Məqsəd hər hansı bir tapşırıq üzərində işləməkdir, lakin biz hələ orada deyilik”.
Termometr modeli yalnız LLM-nin daxili işlərinin kiçik bir hissəsinə daxil olmalıdır ki, müəyyən bir tapşırığın məlumat nöqtələri üçün proqnozunu kalibr edəcək düzgün temperaturu proqnozlaşdırsın.
Effektiv yanaşma
Əhəmiyyətli odur ki, texnika birdən çox məşq tələb etmir və LLM-i yalnız bir qədər yavaşladır. Üstəlik, temperatur miqyası modelin proqnozlarını dəyişdirmədiyi üçün Termometr öz dəqiqliyini qoruyur.
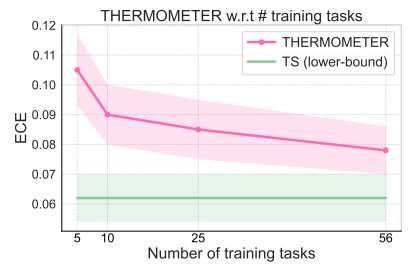
Onlar Termometri çoxlu tapşırıqlar üzrə bir neçə baza ilə müqayisə etdikdə, o, ardıcıl olaraq daha az hesablama tələb etməklə daha yaxşı kalibrlənmiş qeyri-müəyyənlik ölçüləri yaratdı.
“Termometr modelini kifayət qədər çox sayda tapşırıq üzərində öyrətdiyimiz müddətcə, o, istənilən yeni tapşırıqda yaxşı ümumiləşdirə bilməlidir, böyük bir dil modeli kimi, o, həm də universal bir modeldir”, – Shen əlavə edir.
Tədqiqatçılar həmçinin tapdılar ki, əgər onlar daha kiçik bir LLM üçün Termometr modelini öyrədirlərsə, bu, eyni ailə daxilində daha böyük bir LLM-nin kalibrlənməsi üçün birbaşa tətbiq oluna bilər.
Gələcəkdə onlar Termometri daha mürəkkəb mətn yaratmaq tapşırıqları üçün uyğunlaşdırmaq və texnikanı daha böyük LLM-lərə tətbiq etmək istəyirlər. Tədqiqatçılar həmçinin Termometr modelini öyrətmək üçün lazım olan etiketli verilənlər toplusunun müxtəlifliyini və sayını hesablamağa ümid edirlər ki, o, yeni bir tapşırığa ümumiləşdirə bilsin.
Ətraflı məlumat: Maohao Shen et al, Thermometer: Towards Universal Calibration for Large Language Models, arXiv (2024). DOI: 10.48550/arxiv.2403.08819
Jurnal məlumatı: arXiv Massaçusets Texnologiya İnstitutu tərəfindən təmin edilmişdir
Bu hekayə MIT News ( web.mit.edu/newsoffice/ ), MİT tədqiqatı, innovasiya və tədrisi haqqında xəbərləri əhatə edən məşhur saytın izni ilə yenidən nəşr edilmişdir .