




Yeni model müxtəlif məlumat girişlərindən audio və musiqi parçaları yarada bilər
Son illərdə kompüter alimləri mətnlər, şəkillər, videolar, mahnılar və digər məzmun yaratmaq üçün müxtəlif yüksək performanslı maşın öyrənmə vasitələri yaratdılar. Bu hesablama modellərinin əksəriyyəti istifadəçilər tərəfindən verilən mətn əsaslı təlimatlar əsasında məzmun yaratmaq üçün nəzərdə tutulub.
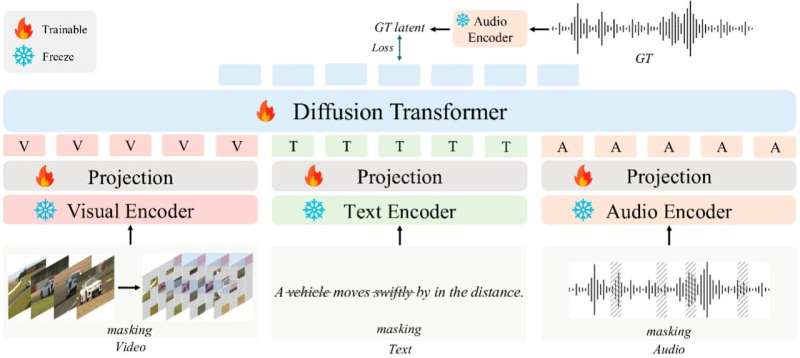
Honq Konq Elm və Texnologiya Universitetinin tədqiqatçıları bu yaxınlarda mətnlər, video görüntülər , şəkillər, musiqi və audio yazılardan giriş kimi istifadə edərək yüksək keyfiyyətli audio və musiqi parçaları yarada bilən AudioX modelini təqdim etdilər. Onların arXiv preprint serverində dərc olunmuş məqalədə təqdim edilən modeli, qəbul etdiyi daxilolma məlumatlarını tədricən aradan qaldıraraq məzmun yaratmaq üçün transformator arxitekturasından istifadə edən qabaqcıl maşın öyrənmə alqoritmi olan diffuziya transformatoruna əsaslanır.
“Tədqiqatımız süni intellektdə əsas sualdan irəli gəlir: ağıllı sistemlər vahid çarpaz modal anlayışa və nəsil əldə etməyə necə nail ola bilər?” Bu barədə Tech Xplore-a qəzetin müvafiq müəllifi Vey Xue bildirib. “İnsan yaradılması problemsiz inteqrasiya olunmuş bir prosesdir, burada müxtəlif duyğu kanallarından gələn məlumat təbii olaraq beyin tərəfindən birləşdirilir. Ənənəvi sistemlər çox vaxt ixtisaslaşdırılmış modellərə arxalanır, modallıqlar arasındakı bu daxili əlaqələri tuta bilmirlər.”
Wei Xue, Yike Guo və onların həmkarlarının rəhbərlik etdiyi son tədqiqatın əsas məqsədi vahid təmsilçilik öyrənmə çərçivəsini inkişaf etdirmək idi. Bu çərçivə fərdi modelə yalnız müəyyən bir məlumat növünü emal edə bilən fərqli modelləri birləşdirmək əvəzinə, müxtəlif üsullar (yəni, mətnlər, şəkillər, videolar və audio treklər) üzrə məlumatları emal etməyə imkan verəcək.Oyna
00:0003:58SəssizParametrlərPIPTam ekrana daxil olun
“Biz süni intellekt sistemlərinə insan beyninə bənzər çarpaz-modal konsept şəbəkələri yaratmağa imkan yaratmağı hədəfləyirik”, – deyə Xue bildirib. “Yaratdığımız AudioX modeli konseptual və müvəqqəti uyğunlaşmanın ikili probleminin həllinə yönəlmiş paradiqma dəyişikliyini təmsil edir . Başqa sözlə, o, həm “nə” (konseptual uyğunlaşma) və “nə vaxt” (müvəqqəti uyğunlaşma) suallarını eyni vaxtda həll etmək üçün nəzərdə tutulmuşdur. Bizim əsas məqsədimiz dünyanı ardıcıllıq yaratmaq və müxtəlif modelləri yaratmaq qabiliyyətini saxlamaqdır. reallığa uyğundur”.
https://googleads.g.doubleclick.net/pagead/ads?client=ca-pub-0536483524803400&output=html&h=280&slotname=2793866484&adk=2520359048&adf=746485419&pi=t.ma~as.2793866484&w=750&abgtt=6&fwrn=4&fwrnh=100&lmt=1744702098&rafmt=1&armr=3&format=750×280&url=https%3A%2F%2Ftechxplore.com%2Fnews%2F2025-04-generate-audio-music-tracks-diverse.html&fwr=0&rpe=1&resp_fmts=3&wgl=1&uach=WyJXaW5kb3dzIiwiMTkuMC4wIiwieDg2IiwiIiwiMTM1LjAuNzA0OS44NSIsbnVsbCwwLG51bGwsIjY0IixbWyJHb29nbGUgQ2hyb21lIiwiMTM1LjAuNzA0OS44NSJdLFsiTm90LUEuQnJhbmQiLCI4LjAuMC4wIl0sWyJDaHJvbWl1bSIsIjEzNS4wLjcwNDkuODUiXV0sMF0.&dt=1744702095563&bpp=1&bdt=1592&idt=2570&shv=r20250410&mjsv=m202504100101&ptt=9&saldr=aa&abxe=1&cookie=ID%3Dfdc40d724f2dca57%3AT%3D1735367325%3ART%3D1744702096%3AS%3DALNI_MYStQ6fUQQQLyo5Z7z1h-XhXcWBtA&gpic=UID%3D00000f80eacffadc%3AT%3D1735367325%3ART%3D1744702096%3AS%3DALNI_MYaOugky0UawScoidzfbXof3-N-iw&eo_id_str=ID%3De43bb863646b60b8%3AT%3D1735367325%3ART%3D1744702096%3AS%3DAA-AfjbQoPwZqH28q9IwcCLRSzzg&prev_fmts=0x0&nras=1&correlator=785417570078&frm=20&pv=1&rplot=4&u_tz=240&u_his=1&u_h=1080&u_w=1920&u_ah=1032&u_aw=1920&u_cd=24&u_sd=1&dmc=8&adx=448&ady=2225&biw=1905&bih=945&scr_x=0&scr_y=0&eid=95355972%2C95355974%2C95357878%2C95356661%2C95356809%2C95357715&oid=2&pvsid=4371551701574047&tmod=758868902&uas=0&nvt=1&ref=https%3A%2F%2Fphys.org%2F&fc=1920&brdim=0%2C0%2C0%2C0%2C1920%2C0%2C1920%2C1032%2C1920%2C945&vis=1&rsz=%7C%7CpeEbr%7C&abl=CS&pfx=0&fu=128&bc=31&bz=1&td=1&tdf=2&psd=W251bGwsbnVsbCxudWxsLDNd&nt=1&ifi=2&uci=a!2&btvi=1&fsb=1&dtd=2575
Tədqiqatçılar tərəfindən hazırlanmış yeni diffuziya transformatoru əsaslı model, rəhbər olaraq istənilən giriş məlumatından istifadə edərək yüksək keyfiyyətli audio və ya musiqi parçaları yarada bilər. Bu “hər şeyi” audioya çevirmək bacarığı əyləncə sənayesi və yaradıcı peşələr üçün yeni imkanlar açır. Məsələn, istifadəçilərə müəyyən vizual səhnəyə uyğun musiqi yaratmağa və ya istədiyiniz treklərin yaradılmasına rəhbərlik etmək üçün daxilolmaların birləşməsindən (məsələn, mətnlər və videolar) istifadə etməyə icazə vermək.
“AudioX diffuziya transformatoru arxitekturası üzərində qurulub, lakin onu fərqləndirən multimodal maskalanma strategiyasıdır” deyə Xue izah edib. “Bu strategiya maşınların müxtəlif məlumat növləri arasındakı əlaqələri başa düşməyi necə öyrəndiyini əsaslı şəkildə yenidən təsəvvür edir.
“Təlim zamanı daxiletmə üsulları arasında elementləri gizlətməklə (yəni, video çərçivələrdən yamaqları, mətndən işarələri və ya audiodan seqmentləri seçmə şəkildə silməklə) və modeli digər üsullardan itkin məlumatı bərpa etmək üçün öyrətməklə, biz vahid təmsil məkanı yaradırıq.”

AudioX bu multimodal verilənlərin semantik mənasını və ritmik strukturunu ələ alaraq linqvistik təsvirləri, vizual səhnələri və audio nümunələri birləşdirən ilk modellərdən biridir. Onun unikal dizaynı ona insan beyninin müxtəlif hisslər (yəni, görmə, eşitmə, dad, qoxu və toxunma) tərəfindən qəbul edilən məlumatları necə inteqrasiya etdiyi kimi, müxtəlif məlumat növləri arasında əlaqə yaratmağa imkan verir.
“AudioX, müxtəlif əsas üstünlükləri olan ən əhatəli hər hansı bir audio əsas modelidir” dedi Xue. “Birincisi, bu, vahid model arxitekturasında yüksək şaxələndirilmiş tapşırıqları dəstəkləyən vahid çərçivədir. O, həmçinin multimodal maskalı təlim strategiyamız vasitəsilə çarpaz modal inteqrasiyaya imkan verir, vahid təmsil məkanı yaradır. O, çox yönlü nəsil imkanlarına malikdir, çünki o, həm ümumi audio, həm də musiqini yüksək keyfiyyətlə idarə edə bilir, yeni seçilmiş kolleksiyalarımız da daxil olmaqla, geniş miqyaslı məlumat dəstləri üzərində öyrədilir.”
İlkin sınaqlarda Xue və onun həmkarları tərəfindən yaradılan yeni modelin mətnləri, videoları, şəkilləri və audioları uğurla birləşdirərək yüksək keyfiyyətli audio və musiqi trekləri hazırladığı müəyyən edilib. Onun ən diqqətəlayiq xüsusiyyəti odur ki, o, müxtəlif modelləri birləşdirmir, əksinə, müxtəlif növ girişləri emal etmək və inteqrasiya etmək üçün tək diffuziya transformatorundan istifadə edir.
“AudioX, bir arxitekturada mətn/video-audiodan tutmuş audio rəngləmə və musiqi tamamlamaya qədər müxtəlif tapşırıqları dəstəkləyir və adətən yalnız xüsusi tapşırıqlarda üstün olan sistemlərdən kənara çıxır” dedi Xue. “Model film istehsalı, məzmunun yaradılması və oyun oynama sahələrini əhatə edən müxtəlif potensial tətbiqlərə malik ola bilər.”
. DOI: 10.48550/arxiv.2503.10522")
AudioX tezliklə daha da təkmilləşdirilə və geniş parametrlərdə yerləşdirilə bilər. Məsələn, o, sosial media üçün filmlərin, animasiyaların və məzmunun istehsalında yaradıcı mütəxəssislərə kömək edə bilər.
“Təsəvvür edin ki, bir kinorejissor artıq hər səhnə üçün Foley rəssamına ehtiyac duymur” deyə Xue izah etdi. “AudioX yalnız vizual görüntülərə əsaslanaraq avtomatik olaraq qarda ayaq səslərini, cırıltılı qapıları və ya xışıltılı yarpaqları yarada bilər. Eyni şəkildə, o, təsir edənlər tərəfindən TikTok rəqs videolarına mükəmməl fon musiqisini dərhal əlavə etmək üçün istifadə edilə bilər və ya YouTuberlar tərəfindən orijinal yerli səs mənzərələri ilə səyahət vloqlarını artırmaq üçün istifadə edilə bilər – hamısı tələb əsasında yaradılır.”
Gələcəkdə AudioX video oyun tərtibatçıları tərəfindən fon səslərinin oyunçuların hərəkətlərinə dinamik uyğunlaşdığı immersiv və adaptiv oyunlar yaratmaq üçün də istifadə edilə bilər. Məsələn, personaj beton döşəmədən otun üstünə keçdikcə, onların ayaq səsləri dəyişə bilər və ya təhlükə və ya düşmənə yaxınlaşdıqca oyunun soundtracki tədricən daha da gərginləşə bilər.
“Növbəti planlaşdırılan addımlarımıza AudioX-i uzun formatlı audio nəsil üçün genişləndirmək daxildir” deyə Xue əlavə etdi. “Bundan əlavə, multimodal məlumatlardan assosiasiyaları öyrənməkdənsə, biz subyektiv üstünlüklərlə daha yaxşı uyğunlaşmaq üçün insan estetik anlayışını gücləndirici öyrənmə çərçivəsinə inteqrasiya etməyə ümid edirik.”
Daha çox məlumat: Zeyue Tian və digərləri, AudioX: Hər Şeydən Audioya Nəsil üçün Diffuziya Transformatoru, arXiv (2025). DOI: 10.48550/arxiv.2503.10522
Jurnal məlumatı: arXiv
© 2025 Science X Network
Download QRPrint QR