



Yeni robot göz bəbəyi təcəssüm olunmuş AI-nin vizual qavrayışını gücləndirə bilər
Ingrid Fadelli , Phys.org
Robert Egan tərəfindən redaktə edilmişdir
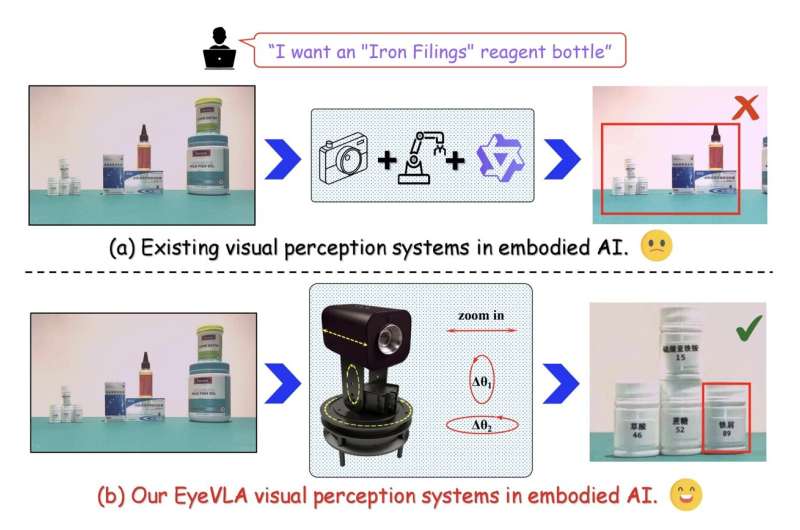
Redaktorların qeydləri(a): Sabit RGB-D kameraları olan mövcud görmə sistemləri daha geniş məkanda incə dənəli vizual məlumatları idarə edə bilməz. (b): Komandanın EyeVLA sistemi təlimatlara uyğun olaraq baxış bucağını fırladıb hədəfi böyütməklə sabit mövqedən daha geniş və daha incə vizual məlumatı qəbul edə bilir. Kredit: arXiv (2025). DOI: 10.48550/arxiv.2511.15279
Təcəssüm olunmuş süni intellekt (AI) sistemləri ətraflarını hiss etmək, hərəkətlərini planlaşdırmaq və həyata keçirmək üçün maşın öyrənmə alqoritmlərinə güvənən robot agentlərdir. Bu sistemlərin əsas cəhəti vizual qavrayış modullarıdır ki, bu da onlara kameralar tərəfindən çəkilmiş şəkilləri təhlil etməyə və onları şərh etməyə imkan verir.
Təcəssüm olunmuş AI agentləri üçün mövcud vizual qavrayış modullarının əksəriyyəti RGB-D kameralarına, həm rəngli (RGB) şəkilləri, həm də dərinlik (D) ilə əlaqəli məlumatları çəkən cihazlara əsaslanır. Lakin əksər hallarda bu kameralar robota qoşulur və yerində sabit qalır ki, bu da dinamik və mürəkkəb mühitlərdə dəyişiklikləri aşkar etmək imkanını məhdudlaşdırır.
Şanxay Jiao Tonq Universitetinin, Çin Elmlər Akademiyasının və Dalian Texnologiya Universitetinin tədqiqatçıları bu yaxınlarda insan göz bəbəklərindən ilhamlanaraq, əlavə sensorlara və ya daha bahalı kameralara ehtiyac olmadan obyektlərin daha aydın təsvirlərini əldə etmək üçün fırlanan və böyüdülə bilən yeni robot sistemi hazırlayıblar. EyeVLA adlanan bu robot göz bəbəyi arXiv preprint serverində dərc olunmuş məqalədə təqdim edilib .
“Mövcud görmə modelləri və sabit RGB-D kamera sistemləri geniş ərazi əhatəsini incə detalların əldə edilməsi ilə əsaslı şəkildə uzlaşdıra bilmir, açıq dünya robot tətbiqlərində onların effektivliyini ciddi şəkildə məhdudlaşdırır” deyə Jiashu Yang, Yifan Han və onların həmkarları öz məqalələrində yazdılar.
“Bu problemi həll etmək üçün biz təlimatlar əsasında fəal hərəkətlər edə bilən, incə dənəli hədəf obyektləri və geniş məkanda ətraflı məlumatı aydın müşahidə etməyə imkan verən aktiv vizual qavrayış üçün robot göz bəbəyi olan EyeVLA təklif edirik.”
Komandanın robot göz bəbəyi və onun əsas modeli
Keçmişdə tətbiq edilən vizual qavrayış üçün bir çox digər robot sistemlərdən fərqli olaraq, bu tədqiqatçılar tərəfindən yaradılan göz almasına bənzər sistem ətrafdakı xüsusi elementləri daha aydın şəkildə çəkmək üçün özünü fırladıb böyüdə bilir. Bundan əlavə, komanda robot göz bəbəyinə istifadəçilərin göstərişlərini emal etməyə və buna uyğun olaraq baxışını dəyişməyə imkan verən maşın öyrənmə modelləri yaratdı.
Onların inkişaf etdirdikləri və gücləndirici öyrənmə yolu ilə öyrədilmiş modellər, digər modellərin sözləri və ya təsvirləri necə proqnozlaşdıra biləcəyinə bənzər şəkildə gələcək hərəkətlərini planlaşdıraraq, kameranın hərəkətlərini “fəaliyyət əlamətlərinə” çevirir. Onlar həmçinin sistemi xüsusi maraq sahələrinə yönəltmək üçün obyektlərin ətrafında 2D qutular yerləşdirirlər.
“EyeVLA hərəkət davranışlarını hərəkət əlamətlərinə diskretləşdirir və onları güclü açıq dünya anlama imkanlarına malik olan görmə dili modelləri (VLM) ilə birləşdirir, görmə, dil və hərəkətlərin vahid avtoreqressiv ardıcıllıqla birgə modelləşdirilməsinə imkan verir” deyə müəlliflər yazırlar.
“Mülahizə zəncirini istiqamətləndirmək üçün 2D məhdudlaşdırıcı qutu koordinatlarından istifadə etməklə və baxış bucağının seçimi siyasətini dəqiqləşdirmək üçün gücləndirici öyrənmə tətbiq etməklə, biz VLM-nin açıq dünya səhnəsini anlamaq qabiliyyətini yalnız minimal real dünya məlumatlarından istifadə edərək görmə dili hərəkəti (VLA) siyasətinə köçürürük.”
Əla performans və mümkün gələcək tətbiqlər
Tədqiqatçılar artıq öz təklif etdikləri sistemi qapalı şəraitdə bir sıra eksperimentlərdə sınaqdan keçiriblər və burada onun daha aydın təsvirlər əldə etmək və onları dəqiq şərh etmək qabiliyyətini qiymətləndiriblər. Onlar sistemin çox bahalı sensorlara və kameralara etibar etmədən olduqca yaxşı işlədiyini aşkar etdilər.
“Təcrübələr göstərir ki, sistemimiz real dünya mühitlərində təlimatlandırılmış səhnələri səmərəli şəkildə yerinə yetirir və təlimat əsasında fırlanma və böyütmə hərəkətləri vasitəsilə fəal şəkildə daha dəqiq vizual məlumat əldə edir və bununla da güclü ekoloji qavrayış imkanlarına nail olur”, – Yang, Han və onların həmkarları yazdı.
“EyeVLA, təfərrüatlı və məkan baxımından zəngin, geniş miqyaslı təcəssüm edilmiş məlumatlardan istifadə edən və aşağı axın yerinə yetirilən tapşırıqlar üçün yüksək informativ vizual müşahidələr əldə edən yeni robot görmə sistemini təqdim edir.”
Gələcəkdə bu tədqiqatçılar qrupu tərəfindən yaradılan göz almasına bənzər görmə sistemi daha da təkmilləşdirilə və daha geniş dinamik mühitlərdə sınaqdan keçirilə bilər. Nəhayət, o, digər robot komponentləri ilə inteqrasiya oluna və real dünya parametrlərində yerləşdirilə bilər.
EyeVLA nəhayət, infrastrukturun, anbarların və ya ictimai yerlərin təftişindən tutmuş təbii mühitin monitorinqinə və məişət işlərinin səmərəli şəkildə yerinə yetirilməsinə qədər geniş spektrli tətbiqlər üçün robotların performansını artıra bilər.
Müəllifimiz İnqrid Fadelli tərəfindən sizin üçün yazılmış, Robert Eqan tərəfindən redaktə edilmişdir — bu məqalə diqqətli insan əməyinin nəticəsidir. Müstəqil elmi jurnalistikanı yaşatmaq üçün sizin kimi oxuculara güvənirik. Bu hesabat sizin üçün əhəmiyyət kəsb edirsə, lütfən, ianə (xüsusilə aylıq) nəzərdən keçirin. Siz təşəkkür olaraq reklamsız hesab əldə edəcəksiniz .
Daha çox məlumat: Jiashu Yang və digərləri, Baxın, Böyütün, Anlayın: Təcəssüm olunmuş Qavrayış üçün Robotik Göz Kürəsi, arXiv (2025). DOI: 10.48550/arxiv.2511.15279
Jurnal məlumatı: arXiv
© 2025 Science X Network