


Zülal dili modelləri üçün dəqiqlik testi süni intellekt “qara qutu”suna işıq salır

Kerol Klark, Emori Universiteti tərəfindən
Stephanie Baum tərəfindən redaktə edilib , Robert Egan tərəfindən nəzərdən keçirilib
Tercih edilən mənbə kimi əlavə edin
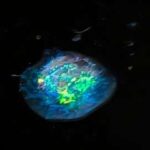
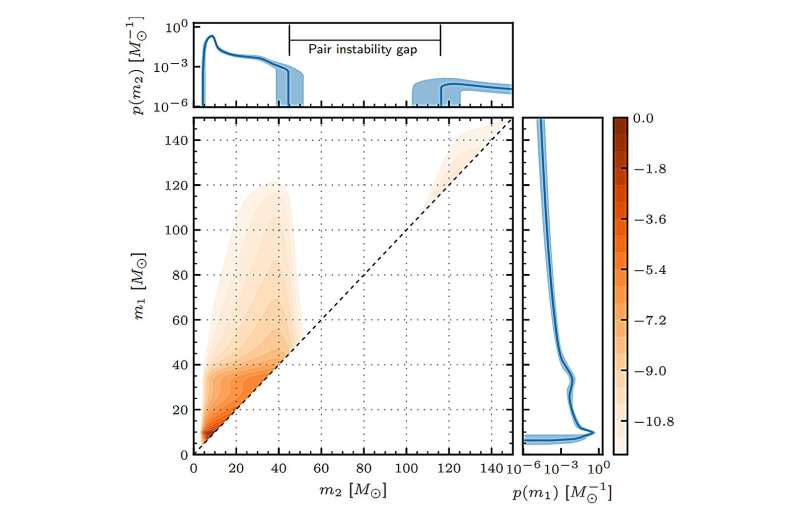
Hər bir zülal, dil modelinin gizli məkanına yerləşdirilmiş bu səpələnmə məlumat qrafikində bir nöqtə kimi müəyyən edilir. Qırmızı, yaşıl və sarı nöqtələr təbiətdə tapılan müxtəlif zülal alt tiplərini, boz nöqtələr isə dil modelinə tanış olmayan sintetik təsadüfi zülalları göstərir. Mənbə: Bromberg laboratoriyası
Çatbotları gücləndirmək və məzmun yaratmaq üçün insana bənzər mətn yaratmaq üçün istifadə edilən süni intellekt dil modelləri, mürəkkəb bioloji məlumatları dil kimi qəbul etməklə biologiyada da inqilab edir. Dil modelləri, məsələn, DNT və zülallarda nümunələr tapmaq, proqnozlar vermək və bioloji mürəkkəblik üzrə tədqiqatları sürətləndirmək üçün getdikcə daha çox istifadə olunur. Lakin, kritik bir boşluq bu proqnozların etibarlılığını qiymətləndirmək üçün bir metodun olmamasıdır.
Emory Universitetinin hesablama bioloqları bu boşluğu aradan qaldıraraq, dil modelinin zülalları anlama dəqiqliyini yoxlamaq üçün sadə bir yol hazırlayıblar. Nature Methods, sintetik təsadüfi zülalları təbiətdə tapılan zülallarla necə yerləşdirdiyini (ədədi olaraq kodlaşdırdığını) müqayisə edərək modelin proqnozlarının etibarlılığını qiymətləndirən sistemini dərc edib .
“Bildiyimiz qədəri ilə, çərçivəmiz zülal ardıcıllığının yerləşdirilməsinin etibarlılığını ölçmək üçün ilk ümumiləşdirilmiş metoddur”, məqalənin baş müəllifi və Emory Universitetinin biologiya və kompüter elmləri üzrə professoru Yana Bromberq deyir.
Tədqiqatın ilk müəllifi və Bromberg laboratoriyasında postdoktorluq tədqiqatçısı olan R. Prabakaran əlavə edir: “Metodumuz mürəkkəb bir problemin sadə və zərif bir həllidir. Bu, elmdə müxtəlif dil modelləri üçün geniş əhatə dairəsinə malik fundamental bir metoddur.”
Yeni metod, yerləşdirmə prosesinə və ya bir dil modelinin müxtəlif növ məlumatları necə kodlaşdırdığına və arxivləşdirdiyinə daha aydın bir baxış verir.
Bromberq deyir: “Biz süni intellektin qara qutusuna işıq salırıq. Dil modelinin necə işlədiyini daha yaxşı başa düşmək, onun etibarlılığını artırmağın və daha yaxşı modellər hazırlamağın yollarını tapmağa imkan verir.”
Gen və zülal mürəkkəbliyini anlamaq
3D formalara qatlanmış uzun amin turşuları zəncirləri olan zülallar, demək olar ki, bütün hüceyrə işi üçün vacibdir. Bir zülalın DNT tərəfindən müəyyən edilən unikal amin turşuları ardıcıllığı, onun spesifik 3D formasını və funksiyasını, o cümlədən reaksiyaları katalizləşdirmək, əzələlərin daralmasını təmin etmək və ya patogenlərə qarşı müdafiə etmək kimi müxtəlif rolları müəyyən edir.
Bromberg, protein və genom analizi üçün maşın öyrənməsinin tətbiqində qabaqcıldır, o cümlədən protein dili modellərinin bioloji məlumatları necə əldə etdiyini anlamaqda. Məqsəd yalnız 3,2 milyard DNT əsas cütündən ibarət olan insan genomunun mürəkkəbliyini açmağa kömək etmək deyil. Bromberg laboratoriyası metagenomları – müəyyən bir icma daxilində yaşayan bütün orqanizmlərdən, o cümlədən mikroblardan genetik material toplusunu öyrənmək üçün lazım olan hesablama texnikalarını inkişaf etdirir.
Məsələn, Bromberg və Prabakaran metagenomik analizlər üçün DNT dil modeli qurdular və bu model bu yaxınlarda Nucleic Acids Research jurnalında dərc olunub .
Metagenomun olduqca mürəkkəb qarşılıqlı təsirləri həm fərdi orqanizmlərin, həm də ekosistemlərin sağlamlığında əsas rol oynayır.
Prabakaran izah edir ki, “Əgər genomu bir ağac kimi düşünsəniz, metagenom bir meşədir. Və ağac kimi, siz də təcrid olunmuş şəkildə yaşamırsınız. Mikrobların bütöv bir ekosistemi bədəninizlə birlikdə yaşayır. Təbiəti tam anlamaq istəyirsinizsə, metagenomikanı başa düşməlisiniz.”
Gündəlik məlumat üçün Phys.org-a etibar edən 100.000-dən çox abunəçi ilə elm, texnologiya və kosmosdakı ən son yenilikləri kəşf edin . Pulsuz bülletenimizə abunə olun və vacib olan nailiyyətlər, innovasiyalar və tədqiqatlar haqqında gündəlik və ya həftəlik yeniliklərdən xəbərdar olun .
Məlumat çatışmazlığı
Bu mürəkkəbliyi öyrənmək üçün süni intellekt alətləri vacibdir.
ChatGPT kimi dil məzmununun yaradılmasının əsasını təşkil edən böyük dil modelləri, müvafiq mətn üçün proqnozlar vermək məqsədilə mövcud insan yazı nümunələri üzərində təlim keçir. Zülal dili modelləri mövcud zülal ardıcıllıqları üzərində təlim keçir, beləliklə, bütün mövcud zülal ardıcıllıqlarının öyrənilməsinə kömək etmək üçün proqnozlar verə bilirlər.
Problemlərdən biri məlumatların nisbi çatışmazlığıdır. UniProt kimi verilənlər bazalarında 200 milyondan çox məlum zülalın ardıcıllığı toplansa da, trilyonlarla daha çox zülalın mövcud olduğu təxmin edilir.
“Mən xüsusilə mikroblarla maraqlanıram”, Bromberq deyir. “Və əksər mikroblar, yəqin ki, 90%-dən çoxunu əvvəllər heç görmədiyimiz və ya öyrənmədiyimiz. Hər mikrob öz genomunun müəyyən hissəsini digər mikroblarla ortaq paylaşacaq. Sual budur ki, istənilən mikrob icmasından zülal ardıcıllığının müəyyən hissəsini götürüb bütün zülalların ardıcıllığı və funksiyaları haqqında etibarlı proqnozlar vermək üçün istifadə edə bilərikmi?”
Bu suala cavab vermək üçün tədqiqatçılar protein dili modellərinin etibarlılığını yoxlamaq üçün bir yol hazırlamalı idilər.
Dil modelinin “zibilxanası”
Yeni test metodunun açarı təkamülün zülalları necə formalaşdırdığını anlamaqdadır. Təkamül həyat üçün vacib olan amin turşusu ardıcıllıqlarını qorumaqla zülallar üzərində fərqli bir iz buraxır. Zülal dili modelləri, bu təkamül imzasını ehtiva edən təbiətdə tapılan faktiki zülallara məruz qoymaqla proqnozlar vermək üçün öyrədilir.
Tədqiqatçılar, bir protein dili modelinin bu bioloji cəhətdən mənalı məlumatı təsadüfi olaraq yaradılan sintetik zülallarla necə təsnif edəcəyini (kodlayacağını) müqayisə etmək qərarına gəldilər.
Dil modelləri məlumatları mücərrəd, gizli bir məkana sıxışdıraraq və oxşar elementləri bir yerə qruplaşdıraraq yerləşdirir.
Bu gizli məkanı zülal “nöqtəsi” yaxınlığının oxşarlığı göstərdiyi səpələnmə qrafiki kimi təsəvvür etmək, dil modelinin təbiətdə tapılan zülalları müxtəlif alt tiplərə görə qruplaşdırdığını və onları əsasən gizli məkanın bir sahəsinə – modelin tanış olmadığı sintetik zülallardan uzaqda ayırdığını ortaya qoydu.
Tədqiqatçılar bu ayrı ərazini “zibilxana” adlandırdılar və bunun aşağı keyfiyyətli, bioloji cəhətdən daha az mənalı yerləşmələr üçün bir alt məkan olduğunu fərz etdilər.
“Təsadüfi qonşu” balı
Onlar daha sonra təklif etdilər ki, zülalın ən yaxın qonşuları ilə qeyri-bioloji ardıcıllıqların yerləşdirilməsi arasındakı gizli məkanda üst-üstə düşmə dərəcəsi modelin yerləşdirilməsinə olan inamı ilə tərs mütənasibdir.
Tədqiqatçılar daha sonra bu əlaqəni “təsadüfi qonşu balı” adlandırdıqları bir şeyə kəmiyyətləşdirdilər. Bal, müəyyən bir zülalın təsadüfi, sintetik ardıcıllıq qonşularının sayını əks etdirir. Təsadüfi qonşu balı nə qədər aşağı olarsa, modelin yerləşdirməyə olan inamı bir o qədər yüksək olar, daha yüksək bal isə qeyri-müəyyənlik göstərir.
Təsadüfi qonşu balının proqnozlaşdırıcı performansın göstəricisi kimi xidmət edib-etmədiyini qiymətləndirmək üçün onlar protein dili modellərinin istifadə olunduğu bir sıra tapşırıqlar üzrə aşağı keyfiyyətli yerləşdirmələri təhlil etdilər. Onlar bu aşağı keyfiyyətli yerləşdirmələrin çox vaxt mənalı biologiyanı əks etdirmədiyini aşkar etdilər.
Alətlərin itilənməsi
Yeni metodun tətbiqi elmi dil modelinin yerləşdirilməsi prosesinin dəqiqliyi üçün daha dəqiq ölçmələr aparmağa imkan verəcək.
Bromberq deyir: “Bunu cərrahın gələcək əməliyyat üçün ən iti bıçağı seçməsi kimi düşünə bilərsiniz”.
Etibarlılığın bu təkmilləşdirilməsi, maşın öyrənmə prosesini təkmilləşdirmək üçün dil modellərinin inkişaf mərhələsində istifadə edilə bilər.
Prabakaran qeyd edir ki, “Bu prosesin hər mərhələsində daha yaxşı keyfiyyət nəzarətinə ehtiyacımız var. Lazımsız məlumatlar üzərində qurulmağa davam etsəniz, səhvlər çoxalmağa davam edəcək.”
O əlavə edir ki, yeni metod kompüter elmindən götürülmüş ölçülərdən fərqli olaraq, bioloji cəhətdən əsaslandırılmış qeyri-müəyyənlik ölçüsüdür.