





Araşdırmalar göstərir ki, ən yaxşı süni intellekt kodlaşdırma vasitələri hər dörd dəfədən birində səhv edir
Vaterloo Universiteti tərəfindən
Sadie Harley tərəfindən redaktə edilib , Robert Egan tərəfindən nəzərdən keçirilib
Tercih edilən mənbə kimi əlavə edin
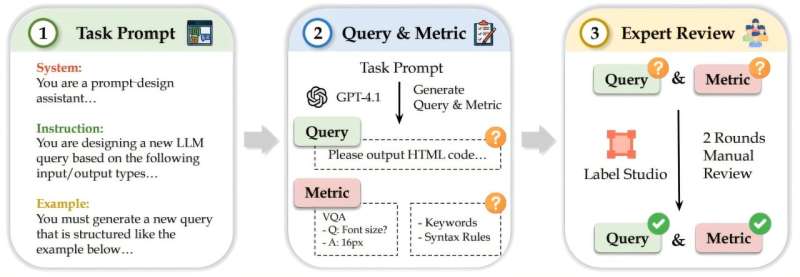
StructEval verilənlər bazasının ümumi dizayn edilmiş annotasiya boru kəməri. Mənbə: arXiv . DOI: 10.48550/arxiv.2505.20139
Vaterloo Universitetinin yeni tədqiqatı göstərir ki, süni intellekt (Sİ) hələ də bəzi əsas proqram təminatı inkişaf etdirmə tapşırıqlarında çətinlik çəkir və bu da Sİ sistemlərinin tərtibatçılara nə dərəcədə etibarlı şəkildə kömək edə biləcəyi ilə bağlı suallar doğurur. Böyük Dil Modelləri (LLM) proqram təminatının hazırlanmasına getdikcə daha çox daxil edildikcə, tərtibatçılar Sİ tərəfindən yaradılan cavabların dəqiq, ardıcıl və daha böyük inkişaf iş axınlarına asanlıqla inteqrasiya olunmasını təmin etmək üçün mübarizə aparıblar.
” StructEval: LLM-lərin struktur nəticələr yaratmaq imkanlarının müqayisəsi ” adlı tədqiqat, Maşın Öyrənməsi Tədqiqatları üzrə Əməliyyatlar bölməsində yer alır və ICLR 2026- da təqdim olunacaq .
Əvvəllər LLM-lər proqram təminatının hazırlanması ilə bağlı suallara sərbəst formada təbii dil cavabları ilə cavab verirdilər. Bu problemi həll etmək üçün OpenAI, Google və Anthropic də daxil olmaqla bir neçə süni intellekt şirkəti “strukturlaşdırılmış nəticələr” təqdim edib. Bu nəticələr LLM cavablarını JSON, XML və ya Markdown kimi əvvəlcədən təyin edilmiş formatlara əməl etməyə məcbur edir və bu da onları həm insanlar, həm də proqram sistemləri üçün oxumağı və emal etməyi asanlaşdırır.
Lakin Waterloo-dan aparılan yeni etalon araşdırması göstərir ki, texnologiya hələ bir çox tərtibatçının ümid etdiyi qədər etibarlı deyil. Hətta ən qabaqcıl modellər belə sınaqlarda yalnız 75% dəqiqlik əldə edib, açıq mənbəli modellər isə 65%-ə yaxın dəqiqlik göstərib.
Tədqiqat, sistemlərin strukturlaşdırılmış qaydalara nə dərəcədə etibarlı şəkildə əməl etdiyini qiymətləndirmək üçün hazırlanmış 18 strukturlaşdırılmış çıxış formatı və 44 tapşırıq üzrə 11 LLM modelini qiymətləndirdi.
Kompüter elmləri üzrə doktorantura tələbəsi və tədqiqatın həmmüəllifi Donqfu Cianq bildirib ki, “Bu cür tədqiqatla biz yalnız kodun sintaksisini deyil, yəni müəyyən edilmiş qaydalara əməl edib-etmədiyini də ölçmək istəyirik, həm də müxtəlif tapşırıqlar üçün əldə edilən nəticələrin dəqiq olub-olmadığını ölçmək istəyirik”.
“Müşahidə etdik ki, onlar mətnlə bağlı tapşırıqları yaxşı yerinə yetirsələr də, şəkil, video və ya veb sayt yaratmaqla bağlı tapşırıqlarda həqiqətən çətinlik çəkirlər.”
Tədqiqat, Waterloo Universitetinin bakalavr tələbəsi Jialin Yang və kompüter elmləri üzrə dosent Dr. Wenhu Chen-in iştirakı ilə aparılan birgə səy nəticəsində həyata keçirilmiş və Waterloo Universitetindən və dünyanın hər yerindən olan 17 tədqiqatçının şərhləri daxil edilmişdir.
Çen dedi: “Son zamanlar laboratoriyalarımızda bir çox oxşar müqayisə layihələri baş verir. Vaterlooda tələbələr tez-tez şərhçi kimi başlayırlar, sonra layihələr təşkil edir və öz müqayisə tədqiqatlarını yaradırlar. Onlar yalnız tədqiqatlarında süni intellektdən istifadə etmirlər – onu qururlar, araşdırırlar və qiymətləndirirlər.”
LLM strukturlaşdırılmış nəticələr proqram təminatının hazırlanması üçün həyəcanverici bir addım olsa da, tədqiqatçılar sistemlərin insan nəzarəti olmadan işləmək üçün hələ ki, kifayət qədər etibarlı olmadığını söyləyirlər. Jiang dedi: “Tərtibatçılar bu agentləri özləri üçün işlədə bilərlər, lakin onlar hələ də əhəmiyyətli insan nəzarətinə ehtiyac duyurlar”.